Insider Spotlight: Genna Sarnak
Welcome to the Insider Spotlight section, where we feature real questions from our team and answers from educators who are making a difference teaching news literacy. This month, our featured educator is Genna Sarnak from Northfield, Massachusetts, where she teaches digital media literacy to middle school students.
 Q: When did you first determine that it is important to integrate AI topics into your teaching?
Q: When did you first determine that it is important to integrate AI topics into your teaching?
 Q: When did you first determine that it is important to integrate AI topics into your teaching?
Q: When did you first determine that it is important to integrate AI topics into your teaching?A: I teach my students how to think critically about the world, from understanding digital footprints and misinformation to reading laterally and finding credible sources. I hope that they leave my class empowered with a toolkit to navigate the often- challenging digital landscape around them.
It quickly became apparent at the beginning of the school year that it was essential to integrate AI into the curriculum. Adults are using AI, including many teachers. Whether we like it or not, students are encountering and using AI as well. I started incorporating it in small ways at first with short quizzes, and students were receptive to them. From there, we moved on to full lessons and practicing using AI chatbots.
Q: How have students responded to learning about AI? Are they generally curious, skeptical, excited?
A: Overall, students are very interested in learning about AI! When we started the “AI or Not?” lesson, students completed the K-H-W-L chart and, not surprisingly, responses ranged all over the board. Some wrote that they heard “AI will take over the world,” that it’s “dangerous,” “will steal your information,” “replace jobs,” or that it’s just generally “bad.” Through the explicit lessons, we’ve been able to explore and break down how AI works (understanding training data and algorithmic bias), the potential pros and cons, the future of AI, and how students themselves can use algorithms to their advantage.
For example, we’ve practiced how to effectively write prompts using AI-generator tools (like ChatGPT), then reflect and improve upon the answers with a second prompt. Tasks like this illustrate appropriate uses of generative AI for students, while also explicitly teaching them how to effectively use keywords (for example, asking it to cite sources or reply with a specific audience in mind).
Q: What are key takeaways students have from the “Introduction to Algorithms” lesson on Checkology?
A: Students learned and were empowered to understand what an algorithm is, how they work, and how to use algorithms to their advantage. This included how they can generate the most impartial and least biased search engine results, curate their newsfeeds, engage with and determine credible sources, and reflect on their own biases. The lesson helped students understand how algorithms can serve them. Students were also able to understand how training data can be flawed and, as a result, biased. I’d say the overall result is that most students now have a better grasp on what AI is, how to determine if an image or text is generated by AI, how to fact- check sources when they’re unsure (and what factors to look for), and how AI tools are changing the nature of evidence for claims.
Q: What is one memorable time of a student having an “aha moment” related to AI?
A: It was really interesting to hear students’ perspectives on the open-ended ethical questions that I posed, such as, “Is it okay for AI to make decisions around who to hire based on job- –seekers’’ resumes, or for doctors to use it when making a diagnosis?” Challenging students to think about the real-life implications of AI answered the “So what?” and “Why does this matter?” that I sometimes encounter from students.
Q: From your experience, do young people have an inherent understanding of technologies like AI, or are they still vulnerable to falsehoods online?
A: In my experience, students are especially vulnerable to falsehoods online, particularly around the media they consume, share, and create. Students certainly do not have an inherent understanding of technologies like AI, and now more so than ever before, teaching digital information literacy and critical thinking skills feels vital.
Q: As our infamous “bird quiz” reveals, identifying AI-generated content can feel like a guessing game! How have you built students’ confidence in their ability to tell what’s real and what’s not?
A: It isn’t always easy, so we talk about transparency and trying to understand what is the main purpose of the content presented to us. I focus on the importance of questioning content before blindly believing it (or worse, reposting it!). Especially with social media and viral posts, I stress the importance of looking at who’s sourcing and posting the information, breaking down the actual claim, what evidence is being cited to support the claim, and then fact-checking using credible sources. We practice this a lot!
I teach students some “clues.” For example, AI-generated images may struggle with drawing hands/fingers, have inconsistencies (people may suddenly disappear, for example), produce blurred text or backgrounds, and or use watermarks and labels to denote they’ve been created with AI. If it quacks like a duck, and looks like a duck, but walks like a dog, something should be sending off alarms in your head, I tell them.
I’ve used resources like the “AI-generated news or not?” slides from The Sift as well to teach about critically analyzing human-created content (an author with a byline) vs AI-generated content (which is cited as such).
Ultimately, though, with the rise of more convincing AI visual technologies, hunting for visual clues alone isn’t sufficient. I teach them that the only real way to identify what’s real or not is to think critically about the context (or missing context) of what’s being posted and to find the original source. Students are encouraged to approach viral posts with skepticism, using their lateral reading and critical thinking skills to look up anything suspicious. They practice with sites like Google reverse image search and Tineye for looking up images, and they use fact-checking sites, including RumorGuard, to find reliable sources for viral claims.
Q: What advice do you have for other educators who aren’t sure how to teach about AI in the classroom, or whether they should teach it at all?
A: Explicitly teaching students AI literacy (such as how it works, when and how to utilize it, and starting a dialogue around potential ethical issues) is essential, and I think it’s important for all schools to address. Ignoring AI or living in fear of teaching about it is a disservice to our students. There are tons of resources out there to help, and if you’re feeling overwhelmed, I’d suggest starting small. Try short daily prompts, or teaching part of a lesson — it doesn’t have to be a massive unit. I often use RumorGuard slides from The Sift newsletter as “mini-lessons” to begin class (as well as the weekly -updated Daily Do Now slides and the AI version). Students understand and respond to these examples because they’re relevant, up-to-date, and — best of all, for me — they’re super easy to implement with very little prep! This is a great starting place.
At a minimum, engaging in an honest conversation with students about AI can be enlightening and useful. In an era of misinformation and disinformation, it’s our responsibility as educators to help students comprehend the world and equip them with the necessary skills for them to succeed. By supporting students with their AI literacy, we can help prepare them for the rapidly changing landscape of information and equip them to build the foundational skills they will inevitably need.
Start teaching about AI
Spend this summer exploring a short and sweet selection of free AI teaching resources from NLP. Dive in right away with summer school students, or explore on-demand professional development opportunities and make plans to jump in when the new school year rolls around. >
Insider Spotlight is a feature of our educator newsletter, The Insider. Subscribe to The Insider for an in-depth look at resources we’ve developed, plus professional development opportunities and more.
NLPeople: Peter Adams, Senior Vice President of Research and Design
Peter Adams
Chicago
1. Can you tell us a little about your background and what brought you to news literacy?

Before joining NLP, I was in education and student media. I started out as a seventh and eighth grade social studies and language arts teacher in the South Bronx in New York City. My principal asked me to bring in grant money for the school. I wrote an application for new science equipment and got it – and then wrote one to support a new student newspaper and got that too.
I had some experience co-founding and publishing an independent student newsletter in my undergrad days, so I took the lead and started the school newspaper.
Later, after going to graduate school in Chicago, I taught humanities and writing courses at two local colleges as well as a student media after-school program for high schoolers in Chicago. I was really hustling in those days … piecing together income several different ways. I loved working with my students and the freedom I had to select readings and design courses that engaged important contemporary issues. My goal was to never tell students what they should think about a given social problem or controversial issue — but rather to make sure they were informed and thinking in careful, logical and critical ways about it.
But as much as I loved this work, I needed to earn more money, so I started to look for something new and found a job listing at a new education nonprofit called the News Literacy Project. (Fun fact: my then-girlfriend, now wife, graduated from Northwestern’s Medill School with a degree in integrated marketing and communications and forwarded me the job posting.)
It was a compelling fit with my background and experience, and I could not have believed in the mission more strongly. I applied and got the job! NLP was less than a year old at the time.
I managed our classroom program in Chicago — helping teachers in middle schools and high schools all over the city integrate news literacy into their classrooms. It was also my job to recruit and prep journalist volunteers to visit NLP schools and guest teach news literacy lessons. It was not a hard sell: Journalists all over the city, from the Chicago Tribune to the Sun-Times to WBEZ to the Chicago bureau of the AP, readily agreed to volunteer. I spent a lot of time in those newsrooms and worked closely with the journalists to design and develop their lessons for students. We prepared our volunteers to go into the classroom with a learning objective and a well-designed activity so the learning was active, engaged and hands-on.
I learned so much about journalism doing this work in partnership with journalists — designing classroom activities and developing lessons with their input and driving them around from their newsrooms downtown to the schools they were visiting … and while I had them captive in my passenger seat, I would pepper them with questions about how their newsrooms operate, about journalism standards and ethics, about things they think the press could do better, and about aspects of their job that they felt were commonly misunderstood by the public. I learned a tremendous amount and continue to draw on these experiences in my role today.
2. What news literacy tip, tool or guidance do you most often use?

I guess fundamentally … trying to be mindful when I’m on social media but really paying attention to my emotions, observing the ways my personal biases are targeted and triggered and being aware of my assumptions.
I also think it’s important to consciously set aside time to seek out quality, standards-based news … not just let news find you through the algorithms that determine your social media feeds. (They don’t exist to inform the public. They exist to keep you scrolling and seeing ads.)
Finally, remembering that our experience of news is highly subjective, intermittent and incomplete. Just because you didn’t happen to see coverage of an issue or event doesn’t mean it doesn’t exist. And when you perceive bias in news you might be right — or it might be that your assessment of the coverage is biased (and other people experienced that coverage differently).
3. You joined the News Literacy Project a year after its founding in 2008. A lot has changed since then. What experience has surprised or impacted you the most?
Well, I guess I’m surprised that our work never seems to get old. The mission is too vital, and the subject matter is so dynamic that I never really feel like I’ve been at one organization for more than 15 years.
As for what has impacted me the most, without question it’s the exposure and access to standards-based newsrooms. The careful practices of verification, the values of honest inquiry, the seriousness with which things like independence, transparency and accountability are regarded … these are abstract things that are palpable when you spend any amount of time in a newsroom or talking with a journalist who is dedicated to their work. We’re always looking for ways to help teach students these same values both so they can recognize them as hallmarks of credible information sources, but also so they will internalize them as they make choices about what to publish and amplify online.
4. Aside from fighting for facts, what else are you passionate about?
Youth baseball. I started coaching when my son started playing about five years ago, and it’s just, as they say, hard not to be romantic about baseball. The history and simplicity of the sport; everything it teaches kids about character and accountability, and about dealing with adversity and accepting plain old bad luck. I also love the kids’ energy and enthusiasm, their sincerity and silliness. It’s what I miss most about teaching. Baseball is one of the only things that completely makes me stop thinking about work. There are a dozen things to think about, say and do just about every moment when you’re running a practice or coaching a game, so I don’t have any bandwidth left for thinking about viral misinformation or worrying about the disappearance of local news. Just for a bit. Long enough to help me recharge and come back to work ready to dive back in.
5. Are you on team dog, team cat, team wombat?
Team dog and it’s not even close. I grew up with Springer Spaniels, but it took me until my mid-30s to find the best one in the whole world. Or rather for him to find me. I’ve rarely been luckier.

Left, Arthur as a puppy. Right, Peter at home with the best Springer Spaniel in the world.
6. Finally, what item do you always have in your fridge?
Some leafy vegetables that are on the verge of going bad. It used to bother me if I didn’t manage to use them up but now, I understand that they’re just the inevitable net difference between the idealized Sunday optimism of the produce section and the frantic realities of the work week for busy parents.
Core values guide us, especially during times of uncertainty
By Chuck Salter
While the seasons change with comforting reliability, upheavals in society are unpredictable. I’ve been reflecting — as I imagine many of you have — on where we are and where we’re headed. Change is happening at a dizzying pace and scale, and with that comes a sense of unease. Uncertainty about the future can make us feel powerless, as though we are at the whims of forces we can’t control, or sometimes even understand.
But we are not powerless.
The work of the News Literacy Project proves that, and I have never been prouder to lead this organization. The nonprofit sector plays a critical role in civic society. It provides vital services on behalf of, and sometimes alongside, the government and works to solve problems where there is no clear profit in the solution. Nonprofits help sustain our social fabric, our democracy and our economy. In 2023 alone, the sector generated more than $1.4 trillion in economic activity — a striking reminder of its reach, resilience and importance. Nonprofits stand up for a community’s values as a collective force, effectively harnessing and multiplying the power of the individual. Your values are reflected in the nonprofits you support, demonstrating how you can make a difference.
Remaining steadfast
NLP, an independent, nonpartisan organization, is grounded in core values that guide us through uncertainty. Among them: News literacy is an essential life skill, facts matter, and a free press is a cornerstone of democracy. We remain steadfast in our mission — especially whenever those values are threatened, or the independence of nonprofits is at risk.
We can’t ignore stark reminders of what’s at stake. Respected news outlets are facing restrictions on access that hamper their ability to cover the nation’s official business. And a decision to cut federal funding for PBS and NPR threatens their ability to fulfill a public good. The 2025 World Press Freedom Index reflects the damage these decisions can do. The U.S. now ranks 57th out of 180 countries, down two spots from last year. We would disagree with these restrictions regardless of which political party issued them. Like news literacy education itself, these issues are not partisan; they concern democracy and a thriving civic dialogue.
Students who learn news literacy understand that a free press protects everyone from tyranny, corruption and government overreach. This is fundamental to the discipline. They learn to think independently, and to apply the standards of quality journalism to navigate disinformation, conspiracy theories and AI-generated fakes. These are skills we all can use.
While the ground may feel shaky, our feet are planted firmly. Our entire team at NLP is more energized and committed than ever to do our part to ensure today’s students are equipped with the tools and abilities they’ll need to be tomorrow’s leaders. On behalf of educators and students in all 50 states, we are grateful for your steadfast commitment, partnership and interest in our work — which we will continue to do until we realize our vision of guaranteed news literacy education for every student in the country.
Chuck Salter is the president and CEO of the News Literacy Project.
Insider Spotlight: Jennifer Liang
Welcome to the Insider Spotlight section, where we feature real questions from our team and answers from educators who are making a difference teaching news literacy. This month, our featured educator is Jennifer Liang from Atlanta, Georgia, where she teaches Media Literacy to high school students with incidence disabilities, like autism and ADHD.
Q: Why are news and media literacy skills important for all learners?
A: Media literacy is important because we want students to mature into active, engaged citizens. I tell my students all the time that they will be voters soon, and I want them to make good choices based on facts.
Q: What are some ways that you’ve adapted NLP resources to meet the needs of your students?
 Q: What are some ways that you’ve adapted NLP resources to meet the needs of your students?
Q: What are some ways that you’ve adapted NLP resources to meet the needs of your students? A: Because I teach special needs, I am always adapting everything. We complete the lesson modules together as a class. That way I can make sure the students fully engage with and understand the content. Because we are reading together, I can help them break down any unfamiliar words or idioms to improve comprehension. Doing it as a group also means that we can discuss answers together. I love it when two students disagree on a response so we can talk through the concept. We make liberal use of the “try again” feature.
Q: How do you supplement Checkology lessons to further student learning?
I add additional readings or videos and assign projects as a summative assessment. Right now, we are working on “Conspiratorial Thinking.” We started the unit by watching a short documentary on the history of the Flat Earth movement. Their final project will be researching a popular conspiracy theory and debunking it. As part of the debunking, they have to identify the types of bias the theory demonstrates and document what kind of harm this theory causes.
Q: What is your favorite tool from the Resource Library, and how do you engage students with it?
A: We refer back to the Seven standards of quality journalism poster all the time. Students have to complete a weekly news article review and rate how well it meets the standards.
Q: What is your favorite Checkology lesson to use with students, and why?
A: The kids get really excited about “Conspiratorial Thinking.” It’s the topic they look forward to all semester.
Want to explore adaptable lessons to teach news literacy skills in your classroom?
- Use Jennifer’s favorite lesson, “Conspiratorial Thinking,” to teach students to recognize conspiracy theories and explain what makes people vulnerable to conspiratorial thinking. This lesson is hosted by Renée DiResta, the former research manager at Stanford Internet Observatory.
- Download Jennifer’s favorite poster, Seven standards of quality journalism. By introducing students to the major standards of quality journalism, and helping them understand their nature and rationale, you’ll provide them with tools that they can use to evaluate the credibility of the information they encounter daily and, in some cases, to critically respond to it.
Insider Spotlight is a feature of our educator newsletter, The Insider. Subscribe to The Insider for an in-depth look at resources we’ve developed, plus professional development opportunities and more.
Trial by Media? The Free Press and the Criminal Justice System
In today’s fast-moving information landscape, journalists play a critical role in uncovering the truth. While social media has opened doors for reporters to reach wider audiences with accessible content, these platforms create additional challenges in the dissemination of credible information.
 Ahead of World Press Freedom Day on May 3, the News Literacy Project hosted a conversation with reporter Meghann Cuniff, a longtime legal affairs journalist, about researching and reporting high-profile legal proceedings, including the role of social media in covering cases involving celebrities like Sean “Diddy” Combs and Megan Thee Stallion.
Ahead of World Press Freedom Day on May 3, the News Literacy Project hosted a conversation with reporter Meghann Cuniff, a longtime legal affairs journalist, about researching and reporting high-profile legal proceedings, including the role of social media in covering cases involving celebrities like Sean “Diddy” Combs and Megan Thee Stallion.
Preview Cuniff’s approach to uncovering events inside the courtroom below and pick up strategies for teaching students about the role of a free press. For more, view the webinar in full on edWeb.
🪄 Demystify high-profile news
Journalists like Cuniff transform complex events into comprehensible reports so the public can stay informed. To make the details of celebrity trials accessible, Cuniff often posts live updates on social media. The platforms create an “escape from the paywalled world of legal journalism,” she said. With this alternative to limited access to articles from legal journals, more people can gain an understanding of what is happening in the courtroom.
Cuniff’s role is especially important given the level of public interest, especially among young people, in high-profile, celebrity trials. With many eyes and ears on these proceedings, Cuniff knows she has a responsibility to ensure that her readers’ understanding of the case and of the legal system itself is shaped accurately.
“There are so many people paying attention to [celebrity cases], that it really shapes their view of the legal system. It’s crucial to provide some education there.”
🤳 Understand citizen journalism
With the decline of many traditional newsrooms around the country, citizen journalists, or individuals without formal journalism training who gather and share information on news events, have stepped onto the scene.
While citizen journalists may unlock information that would not have otherwise been widely available, their existence emphasizes the need to ask questions about the basis for a reported story, Cuniff said. Citizen journalists often are not trained in the standards or ethical practices of professional journalists.
News literacy skills like understanding standards of quality journalism and investigating the source help ensure that internet users can sort through credible reporting and avoid spreading falsehoods.
“It’s a good reminder about the need to educate people about news literacy, what you’re reading, what you’re consuming, and who’s using primary sources.”
💨 Take a breath
When reporting a trial, Cuniff may only have a ten-minute break in the action to post updates for readers. To ensure that she does not sacrifice accuracy in her mission to get breaking news out quickly, Cuniff has a simple practice: taking a deep breath and slowing down.
Cuniff prioritizes using her news judgment to get the basic, most important details out first, recognizing that the nuances of the story can come later, once they have been confirmed.
Just as Cuniff does when she is reporting breaking news, readers can follow the same practice of slowing down and pausing before sharing information online. Taking a few extra minutes to explore the source behind a claim and looking for confirmation from multiple sources goes a long way in curbing the spread of falsehoods.
“It’s all about trying to take a deep breath and to calm down and then focus on the basics.”

Do your students know their First Amendment Rights?
A core standard of news literacy involves acknowledging the importance of the First Amendment and a free press to an informed public. In “The First Amendment,” a FREE interactive lesson on the Checkology® virtual classroom, students learn why the First Amendment’s five rights and freedoms are vital to American democracy. Through case studies, they will weigh in on Supreme Court decisions in which these protections were challenged.
How AI Shapes What We See (And What We Miss)
From shaping our social media feeds to influencing the news we see, algorithms and artificial intelligence are transforming the way we consume information. But how do these technologies work, and what impact do they have on our ability to distinguish fact from fiction?
To get to the bottom of these questions, the News Literacy Project hosted a conversation with reporter Mia Sato, who covers the tech world and AI’s influence for The Verge. Attendees left equipped with strategies to help students develop a more critical approach to digital news consumption. Preview Sato’s takeaways about AI and algorithms below, and view the webinar in full on edWeb.

“AI tools allow users to flood the zone with more content – not necessarily better content.”
👀 Have a critical eye
Synthetic content is everywhere. AI-generated images permeate social media feeds, search engines use AI to synthesize short answers to users’ questions, and news sites may include AI-generated “takeaways” at the top of stories.
To spot synthetic content as you scroll, Sato recommends paying attention to the details. When examining images, zoom in and analyze any images of people, as most AI technologies still struggle to depict human anatomy with complete accuracy. Clothing or hair that disappears into a body? Mangled hands or extra fingers? There’s your sign it might be AI-generated. You can similarly spot AI-generated audio by focusing on the details. Does the voice have an unnatural, robotic cadence? Check the source of the content and confirm with other credible sources — it might be AI-generated.
Clues may be hard to find in visuals or audio. So, don’t neglect to consider factors like:
- Are other news outlets covering the “story”?
- Who is elevating and spreading the story? Is their motive to inform or to profit?
- What are other users saying?
“Tech companies optimize for engagement, time spent, and growth – not necessarily what users want, what’s more accurate, or what’s ‘right.’”
⚙️ Remember the algorithm
In addition to generating images, text, or audio, AI and machine learning also influence the systems that put that synthetic content in front of our eyes. Algorithms are complex webs of instructions and computations that affect everything from the order that links appear in when we conduct a Google search to the restaurants that populate when we open food delivery apps.
These days, social media is not limited to posts from people we choose to follow. It is an abyss of content from creators around the globe, all of which algorithms may choose to put on our feeds.
Algorithms focus on showing us content we are likely to be interested in and likely to engage with. Sato reminds us: Do not rely on social media platforms to show you diverse content or a range of perspectives. Online experiences are highly personalized.
“Algorithms can be very opaque. That’s why they’re sometimes called a ‘black box,’ because nobody can really see into it, even the developers who created the algorithms.”
🪞 Reality check
Our social media feeds and internet search results are closely aligned with our lives and interests. The internet no longer polarizes people, Sato said; it fragments them into small silos of reality.
“It’s easy to lose sight of what everyone else is looking at,” Sato said, but it is important to remember that everyone’s digital experience looks different, and the stream of content fed to one individual is not necessarily representative of reality on a broad scale.
“Platforms are not just pushing people apart, but they’re making small, siloed bubbles of reality.”
Teaching about AI is easier than you think
Looking for an easy point of entry for students to start thinking about AI and responsible online habits? NLP’s “Introduction to Algorithms” lesson on the Checkology® virtual classroom introduces students to algorithms, search engines and AI tools while prompting them to weigh the civic and social impact of these technologies. And, it’s free!
Need an option for younger students? Try “For Elementary: Search and Suggest Algorithms.”
Insider Spotlight: Candice Roach
Welcome to the Insider Spotlight section, where we feature real questions from our team and answers from educators who are making a difference teaching news literacy. This month, our featured educator is Candice Roach from Port Jervis, New York, where she teaches a middle school course called Multimedia Experience. To help students identify credible evidence, Candice uses resources like the “Levels of Scientific Evidence” infographic.

Q: Evaluating evidence for its credibility is a foundational news literacy skill. What are key characteristics of authoritative sources and credible claims?
A: Not all sources are created equally. Obviously, peer-reviewed journals are going to be more authoritative than TikTok. Credible claims are those that can be verified. If a claim is online and true, it should be easy to find it in more than one place.
Q: How is news literacy relevant to your teaching of research skills?
A: News literacy is key to information literacy. Teaching students to find reliable, trustworthy information from verifiable sources is a research skill. It can be transferred to learn any content in any class.
Q: In your experience, what are some common misconceptions that students have about the credibility of sources? How do you address those misconceptions?
A: Lately, students are too trustworthy of AI! Students tend to be trustworthy in general — if someone says it, they believe it. My job is to encourage them to do a lateral search or a reverse image search and verify the information is true before they share it.
Q: How can formal research skills translate to a student’’s consumption of information on social media?
A: It is all related. Verifying information is a skill that can be used in the library, ELA, social studies or on social media. If they aren’t verifying, they may be spreading misinformation.
Q: Why is the ability to evaluate evidence important across subject areas?
A: I want my students to be well-informed. They should be confident in finding information, sharing it and citing it. This will help them do their own thinking, not just regurgitate what they are being told. It gives them agency to learn whatever they want.
Want to help equip your students with the skills to evaluate credible evidence?
- Assign “Evaluating Science-Based Claims” on the Checkology® virtual classroom. Students will learn how to recognize science-based claims and assess their credibility; explore why people resist and deny science; and gain the skills to evaluate science journalism. This lesson is hosted by science educator Melanie Trecek-King.
- Download “Levels of Scientific Evidence” an infographic that presents eight distinct levels of scientific evidence, arranged in a pyramid that reflects a spectrum of quality.
Insider Spotlight is a feature of our educator newsletter, The Insider. Subscribe to The Insider for an in-depth look at resources we’ve developed, plus professional development opportunities and more.
District fellowship drives news literacy instruction at Colorado school

Bright decorations adorned the entrance to the Crested Butte Community School library. Photo courtesy of Erica Young
For a few weeks last fall, the Crested Butte Community School library looked like a party venue. A balloon archway welcomed visitors. Posters brightened the room. Twinkling “chandeliers” caught the eye. Students chatted excitedly as they moved from one activity to the next.
But behind the Colorado school’s dazzle, something important was happening. A three-week-long initiative, “Think Smart, Spot Truth,” was helping students become more news-literate.
The event — and the professional development and news literacy instruction underpinning it — was made possible with help from the nonpartisan News Literacy Project’s two-year* News Literacy District Fellowship program. In 2023, the Gunnison Watershed School District, where the K-12 school is located, was accepted into the program, which provides districts with support and funding to develop news and media literacy instruction.
“When I first learned about the News Literacy Project, I was immediately attracted to the mission and what it stood for — that it’s a nonpartisan nonprofit and is teaching kids the skills to navigate our digital world,” said District Technology Integration Specialist Katie Gallagher, who submitted Gunnison’s application.
Educators Katie Gallagher and Keely Moran make plans for the next school year during the News Literacy Project’s annual convening of district fellows in La Jolla, California, in March 2025. Photographer: Melissa McClure for the News Literacy Project
To start, she led professional development sessions to raise awareness about news literacy education and introduce NLP’s free resources. In spring 2024, Gallagher and K-12 Instructional Coach Keely Moran attended NLP’s annual gathering of fellowship districts. The sharing of ideas and resources galvanized them. Gallagher and Moran decided to create a program that would demonstrate how educators can weave news literacy into their teaching while also getting students excited about learning essential digital literacy skills.
“Meeting with other districts and hearing what they had done was really exciting. The work is important and relevant to kids’ lives. It was the moment that made me want to dive deeper,” Moran recalled.
Fellowship funding helped make program a success
They then joined forces with K-12 Library Resource Specialist Erica Young, who transformed the library into a lively student space with contests, quizzes, challenges and activities.
“Without the fellowship, we would not have had the funding to make it as big and exciting as we did,” Moran said. She added that access to NLP’s free, nonpartisan resources was vital. “This adds to the credibility of what the News Literacy Project is all about, which is really a nonpartisan way of getting our kids to just think critically. It’s essential that it’s all free.”

The vibrant library setting included news literacy activity stations. Photos courtesy of Erica Young
The team developed resources and guidance that teachers could integrate without adding to their already-full plates. “It was helpful to be able to say to teachers, ‘I know every minute counts, and we are supporting your standards,’” Young said.
They also created a slide deck describing news literacy learning standards and how they intersect with different disciplines. They also tied each week’s events to classroom-ready resources.
Students in grades 6-12 focused on reverse image searching (identifying the original source of photo or other visual media) and lateral reading (verifying the credibility of information by consulting multiple, standards-based sources.) Activities for younger grades stressed digital citizenship skills.
“It was important for us to not have it be just a fluff, fun thing to do in the library, but relate it to [learning] standards,” Young noted.
Yet, they did not sacrifice fun. Students and educators who participated in meaningful ways were eligible for prizes. For example, students competed in a “rumor of the day” contest using NLP’s RumorGuard® digital learning tool that required them to explain why a post was false based on five factors for credibility. Teachers completed Bingo cards for each classroom activity they led, including a lesson from the Checkology® virtual classroom. As a final assessment, students were encouraged to create their own PSAs to showcase what they learned. Ninth grader Max Bostick’s entertaining and instructive PSA focused on lateral reading. Watch it here.
Tips for a successful news literacy program
- Demonstrate to educators how news literacy concepts intersect with their learning standards.
- Provide educators with classroom-ready resources for teaching a news literacy concept and have students to practice skills.
- Reach more students by encouraging educators across a discipline to teach the same resource.
- Use timely examples of misinformation that students find engaging; such as doctored images of celebrities.
- Incentivize event participation for students and educators with prizes.
- Tie activities to a current event while keeping it nonpartisan.
Building momentum, making a difference
Young later saw evidence that students retained what they learned. While helping ninth graders with a research project, she observed them use lateral reading skills to determine if their sources were credible.
The team intends to hold the event again in the fall and hope to weave news literacy learning throughout the school year with virtual visits from journalists participating in NLP’s Newsroom to Classroom program.
Gallagher hopes the momentum only continues to grow and helps make possible a future where news literacy is universal. “If this was in every classroom and every school in our state or in our country, it would literally change how our world goes around. I think the impact would be beyond significant.”
*Starting in fall 2025, fellowships will last three years.
To learn more about the district fellowship program, visit: https://newslit.org/district-fellowship/
News Literacy Learning Standards
The News Literacy Project has established five learning standards that define the core competencies for high-quality news literacy education:
- Information type
Students distinguish news from other types of information and can recognize both traditional and nontraditional advertisements. - Free press
Students appreciate the importance of the First Amendment in American democracy and of a free press to an informed public. - Credibility
Students understand why professional and ethical standards are necessary to produce quality journalism and apply understanding of those standards to discern credible information and sources for themselves. - Verify, analyze and evaluate
Students demonstrate increased critical habits of mind, including effective verification skills and the ability to detect misinformation and faulty evidence. - Citizenship
Students express and exercise civic responsibility by seeking, sharing and producing credible information as effective participants in a democracy.
Insider Spotlight: Noreen Fitzgerald-Makar
Welcome to the Insider Spotlight section, where we feature real questions from our team and answers from educators who are making a difference teaching news literacy. This month, our featured educator is Noreen Fitzgerald-Makar from New York City, where she is an English and journalism teacher.

Q: Why is it important for students to understand the First Amendment when learning about news literacy?
A: I think that it is important for students to have a working background knowledge of the First Amendment before learning about news literacy because understanding freedom of press and speech is essential to the practice of being a good journalist and a good citizen. Students need to know what can and cannot be said, to be able to differentiate between opinion and fact, and to understand that First Amendment freedoms allow the press to act as a watchdog. One thing I like to ask students that are interested in joining the class is, “Should governments be permitted to censor news media?” A good number of them say “yes,” and it is then my job to explain why that can never happen.
Q: How does understanding the First Amendment’s protected freedoms help students become more informed, critical consumers of news?
A: I think that understanding the First Amendment’s protected freedoms helps students because they are able to add their own voices to conversations concerning news. Knowing that they have a voice, and they can use that voice to advance a cause or convey a dissenting opinion on a controversial topic, is important.
Q: What strategies for assessing modern issues do students gain by analyzing landmark Supreme Court cases in this lesson?
A: Students learn to make connections between what has already happened and what is going on in our schools/classrooms/communities today. Students can analyze and synthesize information, for example, about why school publications are run as they are run and why change may not be possible. These real-world cases put a face on the issue and make the students more invested in learning about it.
Q: How does learning about the First Amendment’s limitations enhance students’ ability to think critically about what is true and what is false?
A: I think that learning about the limitations of the First Amendment enhances students’ critical thinking because it encourages them to engage with complex questions about the balance between freedom of expression and public responsibility. Students are challenged to consider where free speech should be protected and where it might conflict with other important values, such as public safety, national security or preventing harm.
Q: How can an understanding of the First Amendment guide students in identifying and confronting censorship and attempts to suppress free speech?
A: By understanding the scope of First Amendment protections, students can more easily identify when their rights are being infringed upon. They will be better equipped to distinguish between protected speech and instances where restrictions may be justified. They can advocate for free speech in situations where it may be unjustly restricted, such as when a school or government entity attempts to limit discussions or protests based on controversial topics.
Understanding bias in the news media
Scrolling through the comments on a news organization’s website or social media page reveals a widespread perception: Many people perceive bias in news coverage. Although, few people find that the news is biased in their favor.
Young people are no exception. Almost 70% of teens believe that news organizations intentionally add bias to their coverage and only present the facts that support their own perspective, according to the News Literacy Project’s survey of teen information attitudes, habits and skills, News Literacy in America.
During National News Literacy Week, the News Literacy Project’s Peter Adams led a webinar for educators that shared practical advice and tips to help students regain trust in credible news and to question faulty beliefs about news media bias that can lead to conspiratorial thinking. Here are some takeaways from Adams’ presentation, which provided educators tools to teach this vital, controversial and complex topic in ways that empower students to meaningfully evaluate the fairness and impartiality of news coverage. (View the recording.)
📉 Be wary of media bias charts and ratings
Some organizations publish charts or rating systems that show where they believe news sites fall on a political spectrum. Although the creators of these rankings claim to make bias within news organizations more transparent, Adams warns against taking the representations at face value. Rankings appear to offer a solution for people looking to “unbias, unspin or decode news coverage,” Adams said. But they imply that bias is present in every newsroom and that the creator of such charts is objective enough to discern how to quantify each news organization. Adams recommends taking a critical look before basing opinions about news coverage on these tools. Analyze not only how they represent different organizations, but the reasoning behind their conclusions.
Adams also notes the importance of differentiating between news reports and opinion pieces. On some media bias charts, opinion pieces are included in a site’s ranking. Opinion pieces, which are not intended to be impartial, should be excluded when assessing whether a site’s news reports are neutral and credible.
“It’s very attractive to think there’s an easy answer key.”
📢 Threats to the watchdog role of the press
The press plays an important role in holding powerful institutions accountable. Credible news reports and investigative journalism can expose wrongdoing, giving the public the information they need to make decisions for themselves. However, if people are quick to label news coverage as “biased” when it includes negative information about a public official or institution that they favor, credible reports run the risk of being dismissed as politically motivated or biased.
In addition to discrediting standards-based reporting, false accusations that watchdog journalism is biased also can disempower individuals. The ability to think critically about information is threatened if individuals can dismiss any coverage that challenges their beliefs as biased. Furthermore, if students believe that no news is trustworthy and that every outlet inherently spins information, they will lack confidence even in credible information.
“If the press exposing corruption for someone that you might support counts as bias in your book, then they really can’t play that watchdog role.”
🪄 A rabbit hole of conspiratorial conclusions
Perceptions of news media bias can quickly turn into conspiratorial assumptions about a news organization’s secret motives, Adams said. Young people are especially prone to conspiracy theories, which offer compelling, exciting narratives to explain issues that are rarely clear-cut.
To guard against this way of thinking, it is important to question the validity of the discourse around news media bias. How much of it is driven by misperceptions or opportunism? Is bias in news always intentional, or might it be implicit and inadvertent?
“When there’s no obvious or discernable bias, people still often perceive it. And these perceptions can quickly give way to assumptions about motives that border on the conspiratorial.”
Bring these tips to the classroom
To help students develop a responsible approach to news media bias, introduce them to the types of bias. Using the News Literacy Project’s free “Understanding Bias” lesson on the Checkology® virtual classroom, students can learn about five types of bias and five ways it can manifest itself, as well as methods for minimizing it. Don’t forget to download our infographic: In brief: News media bias.
Register now to access “Understanding Bias.”
Newsweek quotes NLP CEO Salter on solution to lack of news literacy
News Literacy Project CEO and President Charles Salter responded to Supreme Court Justice Sonia Sotomayor’s comments on the need for news literacy in preserving democracy, while underscoring NLP’s focus on a solution. “We agree with Justice Sotomayor that the lack of news literacy skills today poses a danger to all of us. But we also see a solution. We are working toward it every day by bringing free news literacy education to school districts across the country, with the goal of ensuring all high school graduates have the ability to think for themselves so they can confidently navigate our information saturated world,” Salter said in a Feb. 12 Newsweek article.
Sotomayor’s comments came during a conversation on media and news literacy with Knight Foundation President and CEO Maribel Pérez Wadsworth. “We will lose our democracy. News literacy is the obligation of all of us to become more knowledgeable to get accurate information,” she said. “You cannot depend upon what people are telling you.”
How investigative journalism tackled the NFL’s concussion problem
Today, most of us know that a professional football player can sustain potentially devastating brain injuries after years of repeated high-impact collisions with other players. That awareness is due in large part to the reporting of investigative journalist Jeanne Marie Laskas, whose 2009 GQ magazine article Game Brain profiled scientists who had made a stunning discovery: Concussions in pro football players could lead to dementia. It was a story the NFL didn’t want the public to know. But Laskas took on one of the most powerful corporations in the country to tell the story of those affected and further explored the issue in her 2015 book Concussion.
As part of the sixth annual National News Literacy Week, the News Literacy Project hosted an online discussion with Laskas, who detailed her reporting and noted the watchdog role that investigative journalists play in a democracy. (View the recording.)

“Journalists are kind of like translators of explaining complex ideas that the regular person at first blush is not going to get.”
🚨 The watchdog role of investigative journalism
Laskas’ reporting centered on Dr. Bennet Omalu, the physician who first discovered and published his findings on chronic traumatic encephalopathy (CTE) in football players. Although Omalu had published his research in scientific journals, the groundbreaking information about the brain damage suffered by professional football players was not reaching the public. A group of scientists hired by the NFL demanded retractions of Omalu’s work, she said.
Journalists like Laskas, who investigate and document abuses by individuals, corporations and government entities, serve as a check on the most powerful institutions. Their reporting ensures that the public has access to the information they need to make informed decisions. In this case, Laskas’ reporting helped bring to light important information that could affect the health, safety and well-being of the public.
As a result of the work of Laskas and other investigative journalists, the NFL has sought to change tackle styles to minimize head-to-head collision, and communities are embracing alternatives to tackle football, like flag football, for youth leagues.
“It’s becoming more and more important that we have a really robust journalist community of folks who are working hard to shed light on things that are getting darker.”
📰 The importance of local news outlets
Investigative reporting takes time and funding, emphasizing the need for credible, local news outlets. Local journalists are aware of the issues, concerns and dynamics of their communities. They have a unique vantage point to uncover corruption in local governments, school boards or businesses that directly affect residents. “We need people to be open to always taking the lid off and saying, ‘What’s really happening here?’” said Laskas.
“There’s stories everywhere that need light shone on them, and if you don’t have the resources and you don’t have the place to publish it, what are we going to do?”
🔍 Evidence at the source
Journalists like Laskas work hard to gather and confirm facts before publishing a news story. They rely on sources that are accurate and fair.
Before you decide to believe a claim, Laskas recommends thinking like a journalist and asking questions about the source’s motivation. Do they have a political or financial interest? Understanding a source’s purpose in distilling information allows consumers to think critically about its validity. Although skepticism is important, be careful to avoid falling into a trap of cynicism, or general distrust of all information.
“Often misinformation comes from someone who has a specific agenda.”
Want to invite a journalist to your classroom?
Through the News Literacy Project’s Newsroom to Classroom program, students learn real-world lessons straight from an expert. Educators can connect with over 150 volunteer journalists to schedule a virtual or in-person classroom visit.
To get started, sign up for a free Checkology® account. Register now to connect with a journalist.
No, the Super Bowl isn’t rigged, regardless of what your social feed says
As the final seconds of the AFC Championship game at Arrowhead Stadium in Kansas City ticked down, and it was clear the Chiefs would defeat the visiting Buffalo Bills, social media provided plenty of explanations and opinions about what had just transpired on the gridiron.
If you were scrolling as a fan of Kansas City or its quarterback Patrick Mahomes, you probably liked and shared posts about his incredible track record in the postseason. Maybe you lauded defensive coordinator Steve Spagnuolo’s aggressive play-calling and the Chiefs’ fourth-down stops on short-yardage situations that proved critical in the 32-29 victory.
But if you were basically anyone else, you likely were inundated with posts about how the NFL is rigged; how Mahomes is untouchable because he is best friends with league commissioner Roger Goodell; and even for the need for microchips in footballs so that clearly biased/blind refs don’t make another bad call, like the one that cost Buffalo a chance at its first Super Bowl victory. There was outrage — lots of it. And there were conspiracy theories — plenty to go around. Even #boycottsuperbowl started trending.
@newslitproject 🏈 Gonna watch the Big Game? Nearly half of teens in our 2024 survey thought the Super Bowl was rigged. Let’s talk briefly about confirmation bias & motivated reasoning + sports fandom #SuperBowl #Chiefs #TaylorSwift #SuperBowlLIX #NewsLiteracyWeek ♬ original sound – News Literacy Project
As someone who works in news literacy and as an avid sports fan and former sportswriter, this reaction to a huge game with huge implications and yes, controversy, was unsurprising. Sports aficionados are a fickle bunch, and confirmation bias and motivated reasoning run wild among fan bases across the globe. Overreactions and hot takes are a part of sports fandom, so I’m not one to make a big deal out of partisans blaming a close loss on the refs.
But I’ve been thinking more about conspiracy theories in sports since the nonprofit organization I work for, the News Literacy Project, released a survey of 1,100 teens late last year. Among many alarming takeaways was this: Nearly half of teens think the NFL playoffs and the Super Bowl are rigged. To be clear, there is zero credible evidence to support this. But with Kansas City and its star QB — along with Chiefs’ tight end Travis Kelce’s superstar superfan girlfriend Taylor Swift — preparing to try to become the first team to win three Super Bowls in a row this Sunday against the Philadelphia Eagles, such false claims are only multiplying. Just imagine if they win!
And here’s where it’s worth thinking about the broader implications, because, sorry folks, sports are a part of the real world. We already live in an era of unprecedented conspiratorial thinking, distrust in institutions and downright cynicism. Safe and fair elections are questioned, journalists are berated for reporting the facts, and the offline harms of social media posts are very real.
Beyond football, we know that teens are exposed to conspiracy theories with alarming frequency on social media — and they’re falling for them. The News Literacy Project’s study found that 80 percent of young people see them at least once a week, and of those, 81% believe at least one. Some of the most frequent narratives teens said they see being pushed: that the 2020 election was rigged or stolen, that the COVID-19 vaccine is dangerous and that the Earth is flat.
Sports events, in many ways, are the last bastion of broadly accepted truth in society. Games are played with winners and losers, and we move on to the next one. Refs make calls — many good, some bad. If you want a comprehensive breakdown of refs’ calls in Chiefs recent playoff games, here you go — just remember that cherry-picking stats is another pastime of conspiratorial thinkers.
I can’t read the minds of the 48% of teens who said they thought the NFL was rigged. Maybe they really believe it; maybe they just don’t care about football.
The bigger point is that this kind of evidence-free, conspiratorial thinking trickles down to those other topics way more important than football. So let me leave you with a field goal’s worth of news literacy tips.
As with any story, I’d encourage those who might think the league is fixed to:
- Go to the source. Who is saying this? What might their motivations be? Are any journalists who cover the league reporting this?
- Examine the evidence. No, a few calls going against your team does not equal collusion.
- And finally, check your own biases. Are you letting your fan-fueled confirmation bias and motivated reasoning get in the way of the facts? It’s possible. As a long-suffering Detroit Lions fan, I can (somewhat) relate…
Jake Lloyd is director of social media at the News Literacy Project.
Nevada lawmakers issue news literacy proclamation

Ebonee Rice, NLP’s Senior Vice President of Educator Engagement, left, joins Nevada state lawmaker Cecelia González in announcing a proclamation supporting National News Literacy Week in Carson City on Feb. 4.
Photographer: Mike Higdon
Nevada state Assembly members Cecelia González and Erica Mosca recognized National News Literacy Week and the importance of news literacy education in an official proclamation on the Assembly floor at the state Legislative Building in Carson City on Tuesday.
The proclamation underscores the critical importance of news literacy in a democracy and highlights Nevada’s commitment to ensuring young people have the tools they need to navigate today’s complex media landscape.
González said the effort is important because news consumers — especially young people — often confuse credible information and misinformation. “In a time where misinformation rapidly spreads, this is something that is very critical to us and something that we look forward to bringing to Nevada,” she said when announcing the proclamation. “Making sure that our students are critical thinkers is very important.”
Empowering young people
National News Literacy Week (Feb. 3-7) is an annual initiative designed to elevate the importance of news literacy in a democratic society and is presented by the News Literacy Project in partnership with news organizations, including USA TODAY.
“We live in an era when rumors spread rapidly, making news literacy more essential than ever. This proclamation reaffirms Nevada’s commitment to empowering young people with the skills they need to discern credible information and engage in informed civic participation.” said Ebonee Otoo, Senior Vice President of Educator Engagement for the News Literacy Project. She attended Tuesday’s announcement.

Photographer: Mike Higdon
González and proclamation co-sponsor Assemblymember Mosca said they plan to discuss expanding news literacy education with the Nevada Department of Education. González said options include introducing bills next session or exploring policy change through other means.
“We don’t want to overburden our very burdened teachers, as a teacher myself, so we’re having conversations about how we can incorporate this,” she said.
The News Literacy Project also will meet with the Nevada Department of Education to discuss expanding news literacy education across the state.
Insider Spotlight: Juan Armijo
Welcome to the Insider Spotlight, where we feature real questions from our team and answers from educators who are making a difference teaching news literacy. This month, our featured educator is Juan Armijo from Las Cruces, New Mexico, where he is an Advanced Placement (AP) United States government teacher.
Q: Why is it essential for students to comprehend the various types and manifestations of bias in news coverage?
 Q: Why is it essential for students to comprehend the various types and manifestations of bias in news coverage?
Q: Why is it essential for students to comprehend the various types and manifestations of bias in news coverage?A: Students get most of what they consider news or media from social media. It is important that students understand the role bias may play in reporting and providing the public with what is taking place. The lesson has some excellent examples. The poster resource is a tool that I used at the start of the school year.
Q: What are the potential consequences of not teaching students how to identify and analyze bias in the media they consume daily?
A: Many times, students are provided information without a clear understanding of how to view and understand the role of bias. If teachers use any media resource and students don’t understand how to decide if and what type of bias exists, this impacts their future as members of the community and cheats them of the ability to determine bias and how that bias impacts the truth.
Q: How might understanding their own biases influence students’ perceptions of media content?
A: We all (teachers and students, etc.) see the world or see our surroundings from the chair we sit in. I always tell my students to look at how we view information, learning and discussions from that perspective.
Q: What strategies from the lesson can students apply to identify bias in news reporting?
A: The section in the lesson titled “What is straight news?” provides an opportunity for students to understand what reporting the facts are and see if there may be bias based on what is reported, how it is reported and what might be left out. Learning the five types of bias (Partisan, Corporate, Demographic, Neutrality and Big Story) is an important part of the process for students in understanding bias.
Q: How does distinguishing between opinion journalism and straight news reporting benefit students’ media literacy?
A: Understanding opinion pieces as opposed to what is news is important to show students that it is OK to form and discuss different viewpoints. At the start of the school year, I had students analyze a print newspaper, which is a perfectly organized type of media dividing news reporting from the opinion page.
NLPeople: Tracee Stanford, Senior Manager of Professional Learning
Tracee Stanford
Chicago
1. What led you to the news literacy movement?
My journey into the news literacy movement has always been guided by my strong connection to youth and mission-based work. Having worked in television news as a reporter and producer, I gained a first-hand understanding of the importance of accurate, ethical journalism. I felt compelled to bring my experience into the classroom, so I transitioned into teaching middle school and eventually high school journalism. Teaching young people how to think critically about the media they consume and giving them the tools to produce their own was incredibly fulfilling.
An experience that deepened my commitment to news literacy occurred during a mission trip to Peru. While there, I volunteered at a small schoolhouse and became curious to learn how the local community received news. I met a young man who showed me the small room where he broadcasted news on a loud public address system, ensuring it could be heard across the village. This experience highlighted the critical role news plays in every community, regardless of its size or location.

Tracee, above, and shown with schoolchildren she worked with during a mission trip to Peru.
2. What news literacy tip, tool or guidance do you most often use?
I always make it a point to read past the headline and check the source. Headlines, especially on social media, can be sensational or misleading. A quick look at the source helps me figure out if the information is reliable or coming from somewhere questionable. If the source seems iffy, it’s worth digging a little deeper. I usually do a quick search to see if reputable news outlets, like the AP or The New York Times, have written about it. These established outlets follow strict editorial guidelines, so we can trust that their reports are based on facts.
3. Before joining NLP, you worked at Free Spirit Media, a nonprofit youth media organization, where you led teams of media educators focused on teaching essential journalism and solutions-based storytelling skills to youth in underserved communities. How did that work prepare you for your role at NLP?
While at Free Spirit Media, I had the privilege of working with amazing teams of creatives dedicated to developing civic-minded youth with advanced video production skills and the ability to use their voice to tell authentic, meaningful stories. My work at NLP is equally team centered. Not only are my colleagues experts in their fields, but they also care deeply about our mission, which is all about empowering youth. Recently, I had the opportunity to feel the energy and enthusiasm of young journalists at a convention I attended for NLP, and it reminded me of why I’m so committed to teaching the next generation how to be responsible consumers and creators of news. As a mom, these values are also present in my home. I’m more intentional than ever about helping my girls understand the importance of journalism and democracy and why it matters.

Tracee and her family.
4. Are you on team dog, team cat, or maybe you just like houseplants?
I was the last person in our home to warm up to the idea of having a pet, especially a furry one. I was fine with a fish, but that was about it. Now, I’m happy to say, I’m officially team dog! When we got our golden retriever, Charlie Brown (or Charlie, Chuck, or Charles, depending on what he’s getting into) he was a tiny little guy who fit inside a box and was a Christmas gift for my daughters. He’s since become their best friend! Having a dog has been a huge learning curve—almost as big as Charlie is now—but he has definitely found his place in our family, and we love him to pieces.

Charlie, the newest family member.
5. And finally, what item do you always have in your fridge?
Honest Kids juice boxes are always in our fridge. I’m guessing this will be the case for a while since my girls still have some growing to do before they’re “too old” for juice boxes—but, honestly, are you ever really? I still enjoy one every now and then!
Insider Spotlight: Cathy Collins
Welcome to the Insider Spotlight section, where we feature real questions from our team and answers from educators who are making a difference teaching news literacy. This month, our featured educator is Cathy Collins from Boston, Massachusetts, where she is a library media specialist.
Q: What makes editorial cartoons a valuable subject for students to study?
A: Editorial cartoon s convey complex ideas concisely, making them accessible for students to interpret and analyze. Students today are very familiar with GIFs and memes, and so editorial cartoons have a familiarity to them in today’s digital world. The visual elements require students to engage with both visual and textual information. The humorous, satirical nature of editorial cartoons tends to especially speak to teens and encourages them to look beyond the literal to find the deeper meaning. By exposing students to a range of cartoons expressing differing views on a wide range of issues, we encourage them to consider multiple perspectives and help them develop empathy.
s convey complex ideas concisely, making them accessible for students to interpret and analyze. Students today are very familiar with GIFs and memes, and so editorial cartoons have a familiarity to them in today’s digital world. The visual elements require students to engage with both visual and textual information. The humorous, satirical nature of editorial cartoons tends to especially speak to teens and encourages them to look beyond the literal to find the deeper meaning. By exposing students to a range of cartoons expressing differing views on a wide range of issues, we encourage them to consider multiple perspectives and help them develop empathy.
Q: How can analyzing political cartoons deepen students’ understanding of media representation and bias?
A: Analyzing political cartoons helps students begin to question dominant narratives in news, social media and other information sources. Visual cues and symbols can contain fair representation or bias and, with practice, students learn how to interpret these cues and symbols for themselves.
Q: What insights can students gain about the power of visual storytelling in shaping opinions?
A: Through analysis of editorial cartoons, students learn that visual storytelling reflects cultural values, providing insights into the power of art and the ways in which imagery shapes public opinion. Students learn that part of the power of visual storytelling is that it hits us on an emotional level and impacts us on a personal level, influencing our perceptions and beliefs. Visual messages tend to stick in our heads.
Q: In what ways might understanding the watchdog role of media inspire students to question authority or advocate for change?
A: Political cartoons hold authority figures accountable by critiquing their actions and decisions. Studying them, students are reminded that questioning authority and not being what I refer to as a “sheeple” is important. Cartoons that highlight social issues, injustice or political corruption may inspire more students to engage in activism and to strive to make a difference in their home communities and the wider world. By demonstrating the media’s role in monitoring government actions, cartoons can motivate students to participate in civic processes and to find their voices in our democracy. We all stand to benefit!
Insider Spotlight is a feature of our educator newsletter, The Insider. Subscribe to The Insider for an in-depth look at resources we’ve developed, plus professional development opportunities and more.
Save the date for National News Literacy Week 2025
Tick, tock … National News Literacy Week is right around the corner. Mark your calendars for Feb. 3-7.
Now in its sixth year, the week is dedicated to highlighting the importance of helping students strengthen their media and news literacy skills so they can successfully navigate today’s complex information landscape.
Educators can get a head start on participating in the week with our free downloadable Activity Planner, a roadmap for teaching a different news literacy learning standard each day during the week. It includes virtual lessons and infographics that simplify adding news literacy to any curriculum.
🗓️ Start planning for NNLW 2025
The planner and other information are available on the National News Literacy Week landing page, where we will soon add details about all the week’s events.
2024: The year in misinformation
Record-breaking hurricanes, the rapid development and use of generative artificial intelligence technologies, anything Taylor Swift, two assassination attempts, and President-elect Donald Trump’s win were among the biggest news stories of 2024. But misinformation often spread as rapidly as the facts about these events did. Here are the top misinformation trends of 2024.
1. Fraudulent election fraud claims
In the weeks leading up to the 2024 presidential election, false claims aimed at casting doubt on the legitimacy of the electoral process were prevalent on social media. The News Literacy Project tracked viral election misinformation and archived hundreds of social media posts. The claims ranged from falsehoods about noncitizens voting to election technology suppliers altering tallies to satellites being used to change vote counts. But widespread voting irregularities have not been found and election fraud claims themselves proved fraudulent.
Newslit takeaway
Determining the source of a claim is key to staying reliably informed, so it’s important to ask where a photo originated or who made the assertion. Some accounts online, for example, are created to deceive people, and many were active during the campaign. In the days before the 2024 election, the FBI reported that Russia was behind several false viral claims, including one video that purported to show ballots for former President Donald Trump being destroyed.
2. Taylor Swift misinformation
Global superstar Taylor Swift’s Eras Tour became the highest grossing of all time in 2024, but among the RumorGuard team she earned a more dubious (and far less formal) title: Misinformation’s biggest star. The singer’s likeness was repeatedly used online to spread false claims, including falsehoods about the 2020 election being stolen, political endorsements and repudiations (of President Joe Biden and both presidential candidates), and claims about climate change and economic inequality. She also became one of the few entertainers to take a strong stance against the spread of disinformation. When President-elect Trump shared AI-generated images of “Swifties for Trump,” the singer released a statement saying: “The simplest way to combat misinformation is with the truth.”
Newslit takeaway
Disinformation is spread online to influence people’s opinions, which is why popular celebrities are often employed as a conduit for those messages. These kinds of false claims can usually be debunked by checking the celebrity’s official social media accounts, reviewing credible news reports or doing a reverse image search.
3. Lies and AI
The rapid maturation of generative AI technologies continues to worry misinformation researchers. Not only have these tools proven capable of creating photo-realistic images and synthetic video, but they can also be used to mimic people’s voices and create content for nefarious websites. But at the same time, a much simpler form of misinformation still reigns supreme: The bald-faced lie. Sheer assertion claims – or false claims presented without any evidence – are one of the most popular forms of misinformation online.
Newslit takeaway
Whether an image is fabricated using AI or a statement is conjured out of thin air, looking for the source (or lack thereof) is an essential skill for news consumers.
4. Assassination attempt conspiracies
Disinformation is fueling a rise in conspiracy theories, which was readily apparent in the aftermath of the assassination attempts against former President Donald Trump. In addition to falsehoods that commonly spread during events like these — including shooter misidentifications, wild speculation around motives and the shooter’s political party affiliation — some turned more conspiratorial as people claimed without evidence that the shootings were coordinated. It’s worth noting that conspiracy theories were not constrained to one side of the political aisle. Rumors aimed at liberals claimed that the shooting was staged by Trump himself to get a boost in the polls.
Newslit takeaway
A gap in credible information in the immediate wake of a breaking news story allows conspiracy theories to quickly take root. Be patient during breaking news events and remember that credible, verified information takes time to emerge.
5. A flood of hurricane rumors
The 2024 Atlantic hurricane season was extremely active and resulted in billions of dollars in damages along the east coast of the United States. While the federal response was praised by Republican governors in the affected states, the false belief that the federal government’s response was inadequate and amounted to little more than a $750 check persists. The claim was amplified by a Russian disinformation campaign to undermine trust in government and deepen partisan divides. Other misinformation included false claims that FEMA was turning away donations and diverting funds for emergency response to the border, that the FAA was restricting airspace to stop rescue missions, and that the government geoengineered hurricanes Milton and Helene to intentionally damage Republican states.
Newslit takeaway
It’s easy to fall for claims that play into our preconceived biases. Learning how to differentiate between biased sources and reputable news is a key part of staying informed.
NLP helps you keep your holiday conversations civil
One of the traditions at NLP is helping people thoughtfully navigate the holidays by ensuring misinformation and conspiracy theories do not derail conversations or damage relationships. Below is an updated version of a post we’ve shared before, just in time for the holidays:
It’s certainly frustrating and discouraging when misinformation makes its way into a friendly conversation. But when it shows up on the menu for your holiday gathering, misinformation can spoil your appetite as well as your relationships with loved ones.
This holiday season, amid polarizing world events, conditions lend themselves to combative conversations and fractured friendships. But it doesn’t have to be that way. Just like you’d prep the side dishes before guests arrive, you can get ready for engaging in civil and meaningful discourse — even with the family’s diehard conspiracy theorist — using the tips and tools NLP provides.
While every scenario is different, following some general best practices can help keep the conversation civil and make the interaction worthwhile. To begin, use the six tips outlined in our downloadable infographic How to speak up without starting a showdown as a guide. (Click here to download the PDF.) You can also share this fun video with your wider circle on social media:
@newslitproject Don’t let misinformation dominate the dinner table this holiday season. Here are a few tips for having productive conversations #Thanksgiving #Misinformation #NewsLiteracy ♬ original sound – News Literacy Project
Further boost your confidence for entering what are likely difficult discussions with four key strategies with four timeless tips from Get Smart About News, our free weekly newsletter for non-educators, which we also feature on our website. (Subscribe here so you can stay on top of trending news literacy topics and resources.)
Happy holidays!
Support a fact-based future this Giving Tuesday!
Giving Tuesday is more than a global day of generosity — it’s an opportunity to invest in the leaders and decision-makers of the future by supporting news literacy. At the News Literacy Project, every day is a step toward equipping educators, students and communities with the tools to discern fact from fiction and make informed decisions based on credible information.
Thanks to our generous supporters, we’ve achieved remarkable milestones (you can read about them in our latest annual report!), but there’s still so much work to do. Here’s what your support makes possible:
- Empowering educators: Tools like Checkology® and resources such as The Sift® are helping teachers integrate news literacy into classrooms across all 50 states and Washington, D.C.
- Reaching students nationwide: NLP’s programs equip young people with critical thinking skills to evaluate the flood of information they encounter every day.
- Spreading the word: With initiatives like RumorGuard™ and National News Literacy Week, we’re creating champions for facts and combating the spread of misinformation.
This Giving Tuesday, help us make an even greater impact. A gift of just $5 a month can fuel the development of resources that thousands of students and teachers use every day for free! Plus, this year, every dollar you give will go even further thanks to a $500K matching challenge from philanthropists Melanie and Richard Lundquist.
You can also amplify our mission by sharing our #GivingTuesday posts on social media (@newslitproject) to help spread the word about the critical need for news literacy education.
Together, we can make news literacy a priority in classrooms nationwide and prepare young people with the skills and knowledge to lead us into a fact-based future.
Donate today to support #NewsLiteracyNow.
Thank you for standing with us to create a more informed and engaged society!
News literacy takeaways from the Misinformation Dashboard: Election 2024
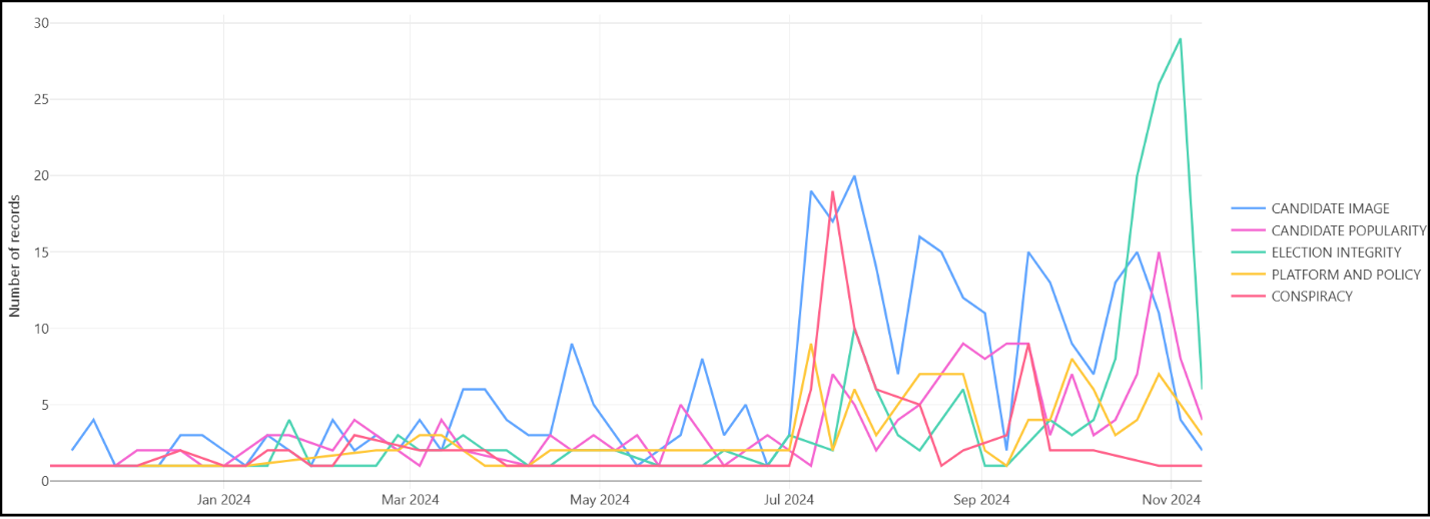
When the News Literacy Project launched the Misinformation Dashboard: Election 2024 last summer, the goal was to collect and track viral falsehoods to help people understand how they develop, and the narratives they attempt to create. With the presidential contest over, it’s time to end the work and review the news literacy lessons it provided.
Lies travel faster than the truth
Misinformation spreads in different ways. A genuine photograph removed from its original context, a manipulated image, or a picture generated with artificial intelligence can all be used on social media as “evidence” for a false claim. But after examining 941 pieces of false content, we found that misinformation spreaders eschew the need to offer any evidence at all. They just simply lie. We catalogued 147 viral falsehoods pushed using this “sheer assertion” tactic — making it the most popular of any we tracked.
AI still looms as a threat
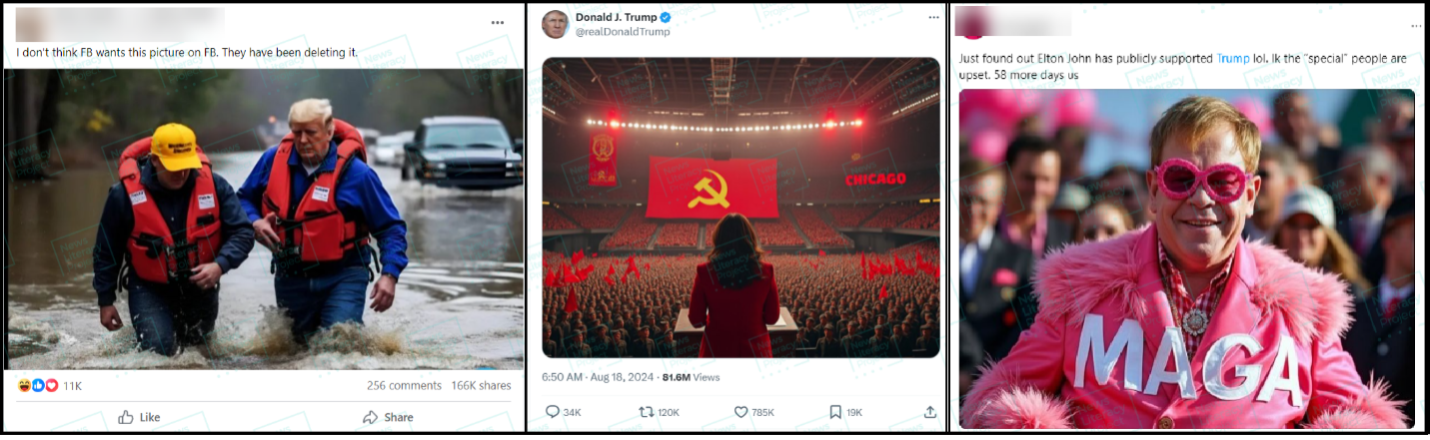
One of unknowns that misinformation researchers faced at the start of election season was how artificial intelligence technologies would impact the information landscape. We certainly tracked falsehoods that were created with AI tools – including videos altered with fabricated voice clones, deepfakes that altered people’s facial movements, and images that looked like photos but were entirely fabricated – but AI-generated content wasn’t as widespread as expected. Only 6% of the 941 examples in the database involved its use.
Even fake popularity matters
Posts that exaggerate a candidate’s popularity made up a surprisingly large number of entries in the dashboard, accounting for nearly 20% of all false claims. Some involved the misrepresentation of crowd size, while others focused on endorsements (or disavowals) of celebrities. Musician Taylor Swift was the most frequently targeted celebrity, but creators of political disinformation also misleadingly cited other public figures and celebrities, such as Keanu Reeves, Michael Jordan, Elton John, Ryan Reynolds and Morgan Freeman.
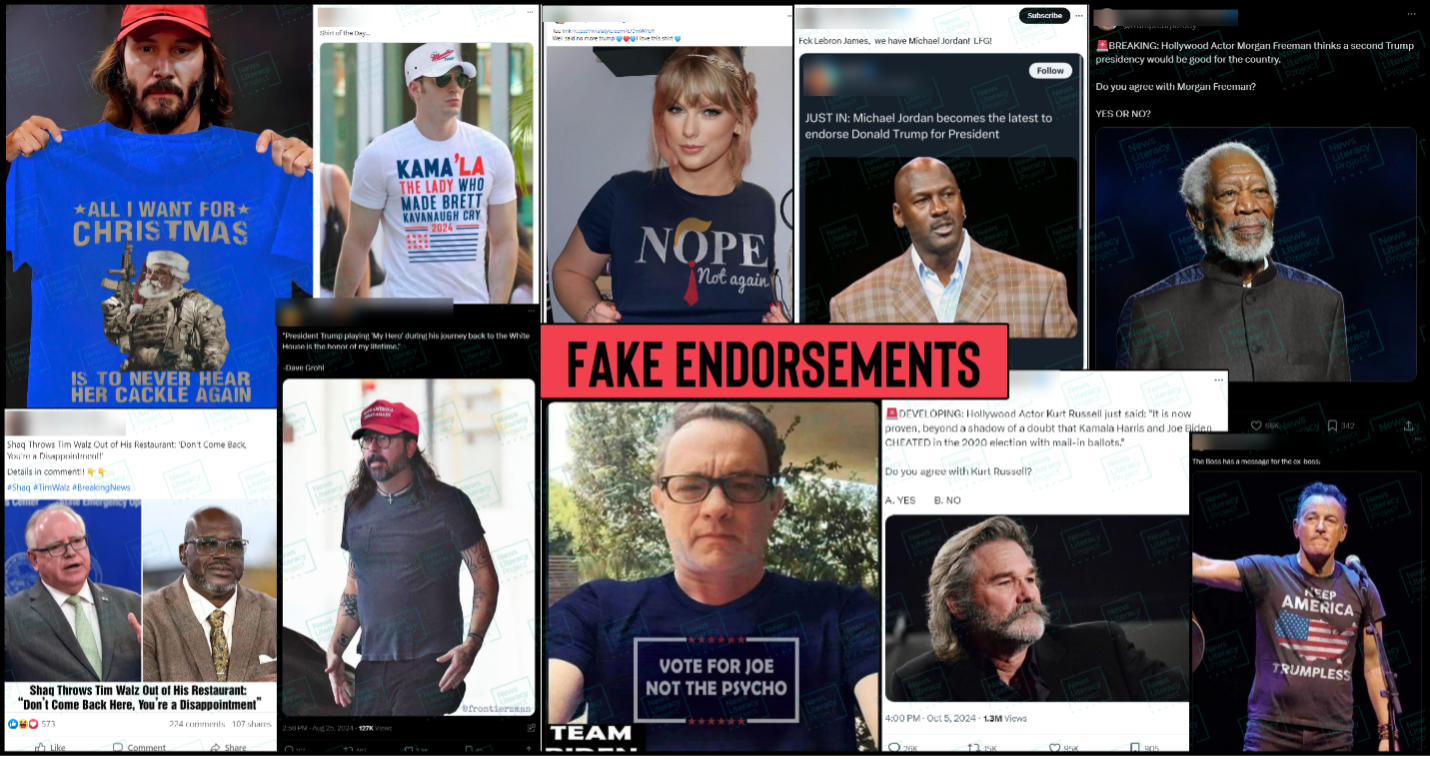
Fitness for office falsehoods grew
The most common narrative pushed by misinformation accounts during election season focused on the fitness of candidates for the presidency. These claims attacked both candidates and President Joe Biden from a variety of angles, including painting them as not smart enough, too old or even too intoxicated to perform the job.
News literacy skills make the difference
One thing all the election misinformation collected in the dashboard has in common: It can be easily debunked, using basic news literacy skills and habits. For example:
Dismissing sensational, evidence-free claims or checking them against high-quality, standards-based sources defuses sheer assertion claims. Reverse image searches put old or manipulated photographs back into their original context. “Lateral reading” (or a quick search for more information from other sources) uncovers credible information to dispel popular but false narratives. And slowing down helps prevent being misled by emotions and vulnerability to confirmation bias.
Falsehoods, of course, persist beyond the election. The misinformation dashboard will continue to be available as an archive. And NLP’s RumorGuard®, which debunks the latest examples of online misinformation, will continue.
Empowering future engineers: An educator’s innovative approach to news literacy
When educator Kelly Melendez Loaiza recently saw an image of a trash-filled catch basin online, she looked past the wet garbage in a hurricane-flooded road and spotted the intersection of news literacy, science and current events.
Melendez Loaiza, who has been teaching for 18 years, joined Davies Career & Technical High School in Lincoln, Rhode Island, this fall to lead its new environmental engineering program, part of the school’s pre-engineering career path. But she has been weaving news literacy into her classes since 2016, when she developed a Science and the Media course at a Massachusetts high school.

Harold Hanka for the News Literacy Project
“If we’re paying attention, we can pull current events in and make media literacy relevant for students,” said Melendez Loaiza, who builds her curriculum around NLP’s Checkology® virtual classroom. “Those lessons are incredible. I couldn’t teach this without Checkology.”
For example, on a recent afternoon, a class of sophomores explored logical fallacies using Checkology’s “Arguments and Evidence” lesson in the context of the pros and cons of nuclear energy, the topic they are currently studying.
Why news literacy matters
Environmental engineers need to be news-literate, Melendez Loaiza believes, because they design systems to protect air, water and the land at the societal level and must interact with community leaders and the public about their work. “They need good communication skills to understand the problems they are trying to solve and the values of the communities they are working with to design solutions that meet the needs of the people being served.”
The catch basin example provided what at first glance looks like a simple issue of trash in a street. But it provides an opportunity for students to use news literacy skills to explore a topic from several perspectives, identifying multiple pathways for solving complex problems. “I bring media literacy back to the science,” she said. “It’s needed to open our minds to all the angles of the problem.”
When her students begin thinking in media literacy terms, the parallels with how they ponder science and engineering emerge and complement one another. Ultimately, it improves their overall critical thinking skills, she said.

Harold Hanka for the News Literacy Project
Students want news literacy education
Melendez Loaiza found that when students begin to practice news literacy, they wonder why they hadn’t been taught it earlier. This sentiment jibes with a key finding from NLP’s newly published study, News Literacy in America: A survey of teen information attitudes, habits & skills (2024): 94% of teens say that schools should be required to teach media literacy. “This should be a basic skill,” student Xavier Dias noted.
Students have also said that learning news literacy skills changed how they engage with others on topics when they disagree. They’ve learned to listen and see arguments from multiple perspectives. “They felt ready to engage in civil discourse because what they had learned quite literally changed them,” Melendez Loaiza said.
Not all information is equal
Melendez Loaiza began her news literacy instruction at Davies High School with the Checkology lesson “InfoZones.” It describes the primary purposes of different types of content, teaching students that all information is not equal. “There can be more to the story than how it’s portrayed,” observed student Jacob Xajap.

Harold Hanka for the News Literacy Project
His classmates also demonstrate understanding of other news literacy key concepts. “When I’m scrolling the news, it’s important to me if there are multiple sources to see if it’s true,” said Aidan Baptista, who recognizes the broader impact of what he is learning. “I feel like it will help me to be more open minded when approaching news and other information.”
‘It can change people’
Melendez Loaiza also teaches Checkology’s “Conspiratorial Thinking” lesson exploring the psychology behind beliefs in this form of misinformation, which teens often encounter. In fact, NLP’s recent survey found that 80% of teens on social media say they see posts that spread or promote conspiracy theories, and of those, 81% say they are inclined to believe one or more.
Student Maddy Lefebvre said that when she encounters likely conspiracy theories, she now has the awareness not to be fooled. “I’ll personally look into it more before believing it.” Classmate Joshua Malmberg agreed. “There’s always something that doesn’t make sense.”
Melendez Loaiza is confident that teaching these future environmental engineers to become more news-literate will help them outside the classroom. It will make them better able to understand current events, be curious but not cynical and communicate with empathy, all of which will be required in their professional lives.
“Every little piece they learn about media literacy is another piece of the puzzle in understanding the world,” she said. “When people are exposed to this in a supportive environment, it can change people and change the world, I believe, for the better.”
Looking back, moving forward: NLP’s FY24 Annual Report
Today, we share our annual report for fiscal year 2024 (July 2023-June 2024). You’ll learn about all we’ve achieved in the past year and how we will move forward with a renewed focus on K-12 education. We hope you feel inspired reading about everything you have helped make possible. Thank you.
Read the report here.
By Greg McCaffery and Chuck Salter
As we prepared this report at the height of the presidential election season, we couldn’t help but reflect on the sheer volume of misinformation being spread.
Falsehoods and distortions will always exist, and with continued advancements in technology and generative artificial intelligence, they spread faster than ever, threatening our country’s civil discourse. We are proud to play a role in helping Americans sift through viral rumors and disinformation with the creation of our Misinformation Dashboard: Election 2024, a tool that tracks the trends and tactics driving misinformation about candidates and the voting process. But more importantly, our goal is to create lasting social change to foster the greater civic engagement needed to strengthen our democracy for generations to come.
This meant taking a critical look at our dual mandate to create a news-literate nation by providing tools, resources, and education to the broader public as well as educators during the past year. As we reviewed our programs, engagement and measurable results, it was clear that we could make the greatest impact by turning our full attention back to K-12 students. We’re excited to refocus our mission on bringing systemic change to public education at a national scale, helping educators across the country align their classroom curriculum with events in the real world — preparing future generations to be engaged citizens.
Our ultimate objective is ensuring that news literacy becomes required teaching in all 50 states and the District of Columbia, just as students are required to learn math, English and social studies.
Because of NLP’s growth on a national scale, we have the flexibility to try new strategies and discover what is most effective. We have leveraged our 16 years of successes and lessons learned to identify the barriers to widespread adoption of news literacy and have developed our 2024-2028 strategic framework as a roadmap for breaking through those barriers. We recognize that our ability to reflect and pivot is due to the encouragement and robust support of donors like you.
As you read this year’s report, you will see that through your partnership, we have much to celebrate. This past year we were recognized with two high-profile awards. And tens of thousands of educators used our resources to teach news literacy skills to nearly half a million students across the country. In addition, through our district-wide initiatives, potentially more than 1 million students in 13 states will be taught news literacy skills by 2026.
We also completed our first teen survey to hear directly from young people about what they know, believe and practice when navigating the digital information landscape.
This is why we see a future full of promise and are confident we will make significant progress to advance the development and teaching of news literacy in K-12 education.
Thank you for being on this journey with us and for continuing to be a champion for a future founded on facts.
Track the trends: Election integrity targeted by online disinformation
The News Literacy Project is tracking presidential election misinformation trends online. As voting day nears, let’s examine some of them, so we can make sure to cast our ballots based on facts, not falsehoods.
A batch of mail-in ballots cast for former President Donald Trump was not destroyed in Bucks County, Pennsylvania; a vacant address in Erie, Pennsylvania is not being used to register illegal voters; and voting machines are not systematically flipping votes in Georgia. The final days of the 2024 presidential election are motivating a spike in falsehoods aimed at undermining confidence in the electoral process in the United States.
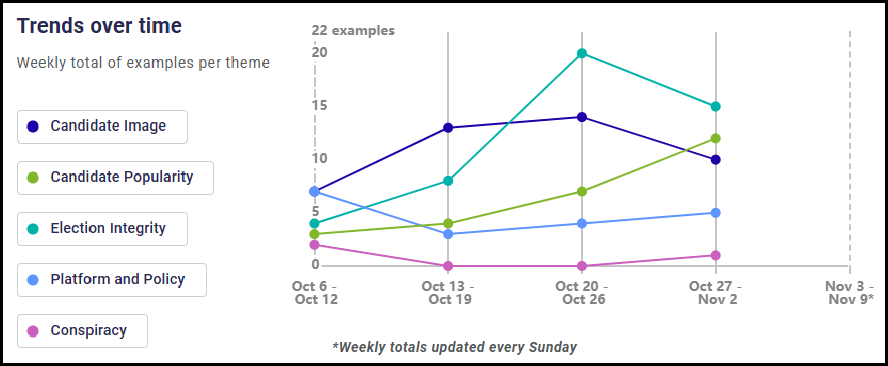
Noncitizens Voting
Falsehoods targeting the integrity of elections make up about 15% of all rumors in the News Literacy Project’s Misinformation Dashboard: Election 2024. These false claims have pushed narratives related to election interference, voter interference, and candidate eligibility, and the most common rumor is that noncitizens are illegally casting votes. Yet, as elections experts have repeatedly pointed out — noncitizens aren’t eligible to vote and instances of noncitizens casting a ballot are extraordinarily rare.
Election Night
Another target of election misinformation is the vote counting process itself. While falsehoods misrepresenting how ballots are being tallied already are frequent, this misinformation theme is likely to expand on election night as votes are counted. Here are a few disinformation trends to expect on Nov. 5:
- Surges in votes being misconstrued as fraud. Remember, counties around the country report their totals in batches, not by individual ballots, so it’s normal to see vote totals jump, especially as larger urban counties report their numbers.
- Premature declarations of victory. Some states have laws prohibiting processing mail or absentee ballots until Election Day, making it difficult to announce a winner on election night. Nonetheless, candidates might prematurely declare themselves a winner and call for vote counting to stop. Delays in reporting results are normal, not voting fraud, and it may take days for states to tally results.
- Individual voting glitches misrepresented as widespread fraud. With tens of thousands of polling places across the country, unexpected things can happen. A power outage, a broken machine or a burst water pipe are just a few. Expect any of these kinds of individual anomalies to be weaponized and spread as evidence of cheating or fraud.
NewsLit Tip: False claims often go viral when they evoke an immediate emotional reaction, especially during a high-profile event like Election Day. Remember to slow down, stay skeptical, and check viral claims against credible sources before sharing sensational content online.
For even more disinformation trends, check out our new prebunking guide, a collaboration between the News Literacy Project and the Mental Immunity Project.
Interested in learning more about the methodology we use to collect election-related falsehoods? Visit the Misinformation Dashboard and click on “Where we get our data.” You can also contribute: Use this form to submit a false claim that is not yet in the dashboard.
Related columns:
Track the trends: Candidate fitness and election integrity rank high in rumors
The News Literacy Project is tracking presidential election misinformation trends online. As voting day nears, let’s examine some of them, so we can make sure to cast our ballots based on facts, not falsehoods.
Fitness for the Job
The most common election misinformation narrative is that a candidate is unfit for the job.
False claims targeting Vice President Kamala Harris paint her as unintelligent or intoxicated. These falsehoods spread through a variety of tactics: short segments of her speeches presented out of context; video of her speaking slowed down to make her words sound slurred; voice actors used to create realistic parodies and quotes fabricated out of thin air. All were presented online as genuine. Be on the lookout for similar claims being pushed with these tactics.
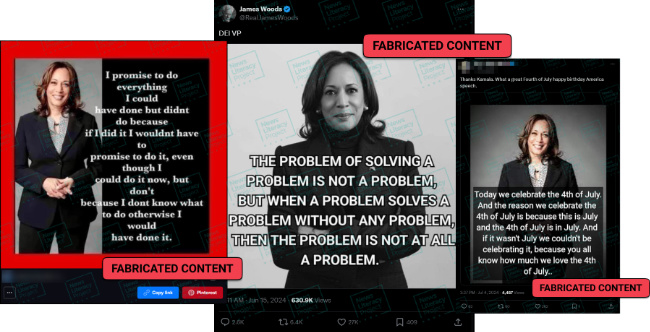
Former President Donald Trump’s mental acuity also is a focus of false attacks, and his physical appearance is frequently distorted on social media.
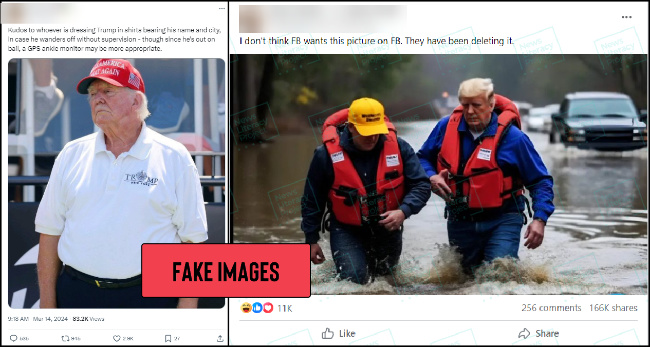
The image on the left circulated widely among Trump’s critics and the one on the right among supporters, but neither accurately depicts Trump. On social media, people can easily get siloed into feeds that provide a politically slanted view — one that feels “right” for the way it resonates with existing personal biases.
NewsLit Tip: NLP’s Misinformation Dashboard: Election 2024 contains numerous misinformation examples that involve distortions related to a candidate’s physical and mental fitness. These falsehoods tend to reinforce preconceived beliefs, so if you have ever thought to yourself, “It might as well be true” after encountering a provocative claim about a candidate, pause for a moment. Reassess your thinking to be sure your opinion of a post is based on accurate information and not your political leaning.
Casting doubt on casting votes
A large portion of the claims in the database target the election itself, with falsehoods attempting to cast doubt about the results. These falsehoods rehashed debunked rumors from 2020, presented standard election procedures out of context, and misconstrued voter registration data. But the most common false narrative in this category is that noncitizens are able to vote.
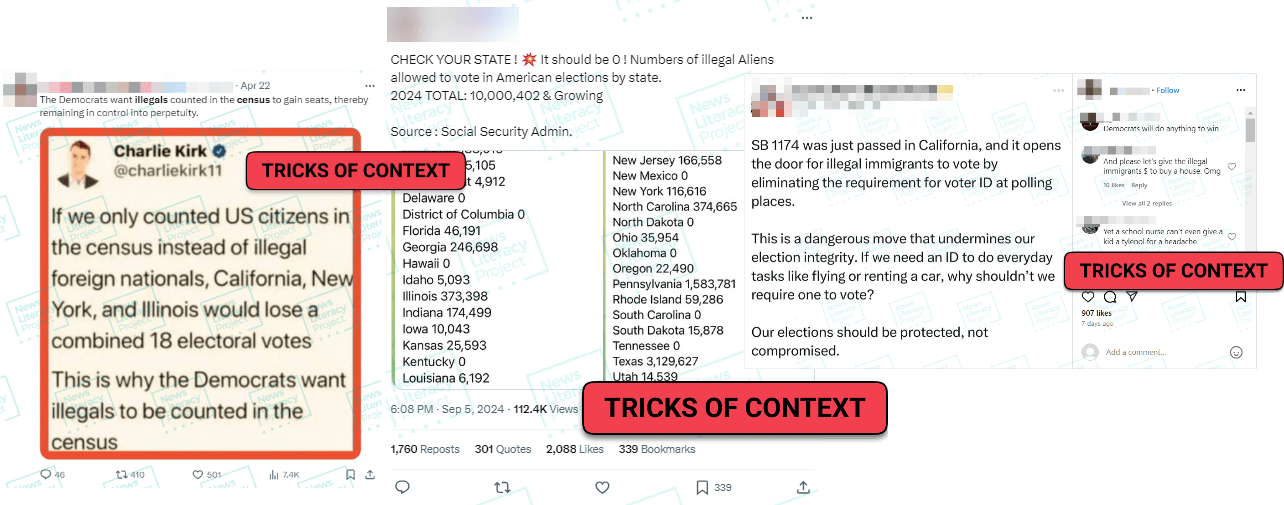
Noncitizens are not legally allowed to vote in the presidential election and there is no evidence to support these voter fraud claims.
False claims about election fraud are bound to spread in the days leading up and following Election Day on Nov. 5, 2024. Be sure that you are getting your information from reputable standards-based sources. And, if you see a shocking claim from an individual account, make sure to check it against standards-based news reporting.
Interested in learning more about the methodology we use to collect election-related falsehoods? Visit the Misinformation Dashboard and click on “Where we get our data.” You can also contribute: Use this form to submit a false claim that is not yet in the dashboard.
Related columns:
Track the trends: Disinformation disguised as ‘breaking news’
Welcome back to our blog series focused on the Misinformation Dashboard: Election 2024, a tool for exploring trends and analysis related to falsehoods regarding the candidates and voting process.
Hours before the June presidential debate between former President Donald Trump and President Joe Biden, an X account posted a “breaking news” story claiming that CNN would implement a one- to two-minute live delay to edit footage before broadcasting it.
The claim was entirely made up, and the word “BREAKING” was used to pass it off as a credible news report. It worked. The post amassed more than 2 million views.
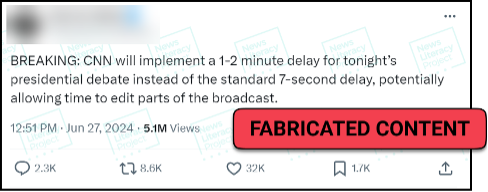
Standards-based news outlets use terms like “breaking news” to signal important developments in an ongoing story. But these alerts have been co-opted by purveyors of disinformation to create fake urgency and spread “breaking” news stories that are neither breaking nor news.
Watch this video compilation of some of the fake “breaking news” we’ve encountered about the election:
The Sheer Volume of Sheer Assertions
NLP’s Misinformation Dashboard: Election 2024 catalogs examples of election misinformation — tracking trends, types and themes. While propagandists have ample tools to create false and misleading content, the most widely used tactic is simply to conjure false claims out of thin air. These “sheer assertions,” as they’re known, make up about 15% of all claims in NLP’s database.
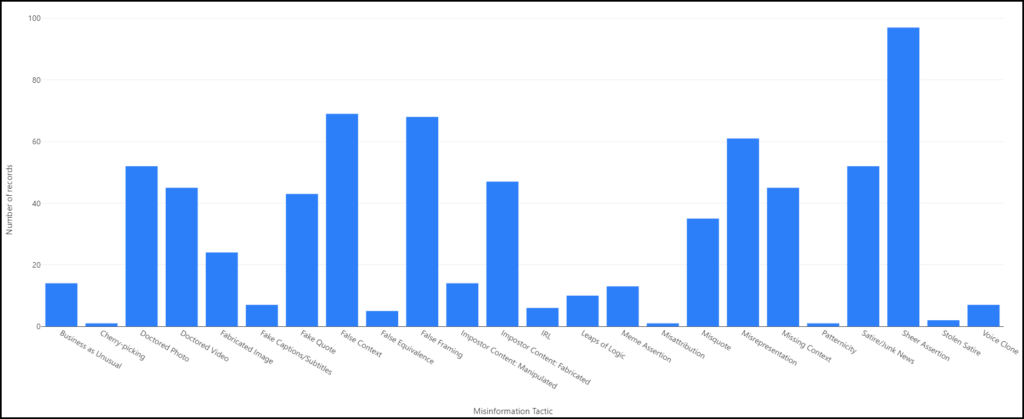
Data from NLP’s misinformation dashboard shows that “sheer assertion” is the leading tactic used to spread misinformation.
On social media, sheer assertion claims about breaking news events are among the fastest to surface and are published recklessly, before all the facts emerge. Journalists report breaking news by interviewing sources, checking data, verifying facts and updating coverage as needed. On the other hand, charlatans — many of whom claim to be doing “citizen journalism” — co-opt journalism lingo to push out baseless speculation or fabrications in mere seconds.
Newslit tip
Social media posts with breaking news language — including “breaking,” “developing,” and “exclusive” — warrant careful examination. Investigate an account’s profile to see if it is connected to a credible news outlet or has a history of publishing accurate information.
Don’t be misled by use of journalism terminology to make these alerts seem authentic. They miss two important aspects of credible reporting: multiple sources and evidence.
As Mark Twain once never said: “A lie can travel halfway around the world while the truth is still putting on its shoes.” Reliable information develops slowly during a breaking news event. Remember that bad actors attempt to fill that void with false claims.
A claim is not evidence
Along with sheer assertions, there are other rumor tactics tied to breaking news events:
- Sensational claims attributed to a single, unnamed “source.”
- Generic photographs that don’t support the claim or add to the supposed story.
- Nonsensical accusations that the media is “ignoring” a story or that a “blackout” has been issued to prevent coverage.
- False attributions to credible news outlets.
Doing real journalism is difficult and takes time. But producing falsehoods of almost any sort is comparatively easy and quick. But of all the tactics people use to spread misinformation, pushing out evidence-free assertions might require the least amount of effort. While this tactic is popular, it is also easy to spot and debunk. Just remember to check your sources, look for evidence and slow your scroll on social media to allow time for credible information to emerge.
This is part of a limited email series that analyzes trends and offers analysis based on the News Literacy Project’s Misinformation Dashboard: Election 2024. Subscribe to the series here.
Related columns:
Top takeaways: 3 tips for teaching news literacy in the age of AI
No longer is artificial intelligence a figment of the imagination. This technology has quickly seeped into everyday life, forcing industries from medicine to education to grapple with its implications. Although AI has the potential to increase efficiency and streamline workflows, it also leads to the proliferation of misinformation in digital spaces. Educators play a vital role in training students to use this new technology thoughtfully, recognize inaccurate and biased information, and make a habit of double-checking before believing.
This fall, EdWeek hosted a forum of experts to explore issues and strategies in K-12 media literacy education. The News Literacy Project’s Shaelynn Farnsworth, District Fellowship Program Director, joined a panel to offer strategies for educators working to build critical thinking skills in their classrooms. Here are three tips to take from the conversation.

“One option that educators simply cannot take is to stick their heads in the sand.” — Kevin Bushweller, Deputy Managing Editor, Education Week
🧶 Weave it in
Critical news literacy skills can be integrated into existing curriculum across subject areas. Don’t be discouraged if your district isn’t yet able to offer a designated media or news literacy course, said Katie Gallagher, a K-12 Technology Integration Specialist in rural Colorado. Weave these skills into your existing classes with support from news literacy standards, like NLP’s Framework for Teaching News Literacy. Include hands-on opportunities for students to engage with technology and AI tools in projects that you already assign, said Cathy Collins, a Library Media Specialist in Massachusetts. For example, science teachers can build examples of misinformation into existing lessons to help students develop key news literacy competencies, like evaluating evidence.
“Start in a place where you can integrate it and embed it into what you already do.” — Katie Gallagher
🫱🏾🫲🏽 Collaborate with colleagues
Training news-literate students requires fostering a news-literate faculty. Engage in professional development days where educators share strategies for helping students navigate today’s technology and information landscape. When teachers better understand the role and impact of AI, their knowledge will ripple down to students, Collins said. When time is tight, consider embedding bite-sized learning opportunities in existing staff meetings or newsletters, added Gallagher.
“Look to teachers that are the trailblazers in your district.” — Cathy Collins
🌱 Set the foundation early
It’s not too soon to start your students down the path of news literacy. Students are gaining access to technology early, meaning that even elementary students need the skills to engage responsibly. About half of U.S. children get their first smartphone by age 11, according to Common Sense Media. Although social media and AI tools often have age restrictions, some young learners still find ways to access these platforms. Building foundational critical thinking skills from an early age will ensure that students are ready to use them responsibly. Focus on honing your students’ conceptual critical thinking skills, said Shaelynn Farnsworth. Help them understand how to seek credible information and gather facts before making a decision.
“Our young learners can start building up those critical thinking skills.” — Shaelynn Farnsworth
🔥 Hot tip: Check out “Introduction to Algorithms”
Looking for an easy point of entry for students to start thinking about AI and responsible online habits? With new content for the 2024-25 school year, NLP’s “Introduction to Algorithms” lesson on the Checkology® virtual classroom introduces students to algorithms, search engines and AI tools while prompting them to weigh the civic and social impact of these technologies. And, it’s free!
Need an option for younger students? Try “For Elementary: Search and Suggest Algorithms.”
NLPeople: Ana Bitter, Design Lead
Ana Bitter
Hawai’i
1. What led you to the news literacy movement?
I grew up in a household of journalists and educators. And in college I worked on the student newspaper (Ka Leo O Hawai‘i), first as a copy editor and later as a designer. So, I’ve always understood the value of being informed and providing good information to others. I came across the News Literacy Project as a new graduate searching for a job during the pandemic.
It felt like just the right opportunity at a time when I was eager to do work that could have a positive impact on a world fraught with problems. I believe design can be a tool for improving universal communication and the greater good. I’m proud to use my design skills in the service of news literacy, and I’ve learned how to be a much better consumer of information in the process.
2. What news literacy tip, tool or guidance do you most often use?
It’s one of the simpler recommendations, but I always try to “slow down” when I’m consuming any kind of information — especially when I’m skimming headlines or posts online. And when I notice myself having a strong reaction to something I see, I really try to take that pause and ask myself what I’m feeling and why, is the content playing on one of my biases?
I also try to be skeptical, which I know can be mistaken for being negative. But I try to view it as approaching information with curiosity. Being skeptical allows you to learn more and dig deeper when something turns out to be credible, and it makes you better at recognizing when something isn’t.
3. You worked on high-profile design projects while still an undergrad, such as a piece that was exhibited in Tokyo Midtown’s “Open the Park” event, an international exhibition, which must have been exciting. What type of design work would you love to do in the future?
 3. You worked on high-profile design projects while still an undergrad, such as a piece that was exhibited in Tokyo Midtown’s “Open the Park” event, an international exhibition, which must have been exciting. What type of design work would you love to do in the future?
3. You worked on high-profile design projects while still an undergrad, such as a piece that was exhibited in Tokyo Midtown’s “Open the Park” event, an international exhibition, which must have been exciting. What type of design work would you love to do in the future?Yes! I had some amazing opportunities during my design BFA (Bachelor of Fine Arts) coursework, which focused a lot on projects that were intended for print and existed as physical objects, like books. We worked a lot with experimental book forms, designing the interiors and exteriors. In fact, it was my passion for books and book covers, in particular, that led me to study design in the first place.
I love the idea that good design gives the information books contain — whether informative or fictional — the best chance of being consumed and enjoyed by a reader. I’ve always wanted to design for a publishing house, (selfishly) so that I could read advanced copies of books before they’re published. I would also love to work on more technical texts like cookbooks, since they have so many fun layers of information to work with. My experience here at NLP designing resources for K-12 students has sparked my interest in designing books for young readers as well.



4. Are you on team dog, team cat, team wombat?
If forced to choose, I would have to say team dog (my dachshund Lila would never forgive me if I didn’t). I truly believe dogs make us better people. But I have recently had my first experience raising a kitten, and I must admit that cats are a lot of fun in totally different ways.
I need to give a shout-out to team bird as well! I’ve had two Eclectus parrots since I was a kid, and while parrots can be challenging pets, they’re truly remarkable animals with a surprising capacity for affection and emotion. I’ve also raised chickens (they’re way smarter than you think) and was 100% that little kid always trying to care for baby birds that had fallen out of their nest. So, I definitely think feather babies deserve some love too!
5. And finally, what item do you always have in your fridge?
I’m not a spicy food fanatic by any means — I really can’t handle much heat. Ironically, I usually have some sort of curry paste or garlic chili sauce at the back of my fridge. I don’t really like working with fresh chilis/peppers when I’m cooking. You have to be careful what you touch, and it’s hard to gauge how much spice you’re actually adding to a dish. But I love making Thai-inspired food, and once you’re familiar with a particular curry paste, it’s easy to add just the right amount of heat along with all its other great aromatic flavors.
Track the trends: Is it AI or is it authentic?
Welcome back to our blog series focused on the Misinformation Dashboard: Election 2024, a tool for exploring trends and analysis related to falsehoods regarding the candidates and voting process.
The prevalence of content generated by artificial intelligence has made it more difficult to differentiate between fact and fiction. Widely available AI tools allow people to create photo-realistic but entirely fabricated images, but how often are these fakes being passed off as genuine and used to spread misinformation and what can we do to identify and debunk them?
One of the goals of the News Literacy Project’s Misinformation Dashboard: Election 2024 is to monitor the use of AI-generated content to spread falsehoods about the presidential race. Now, with about 700 examples cataloged, let’s look at the impact.
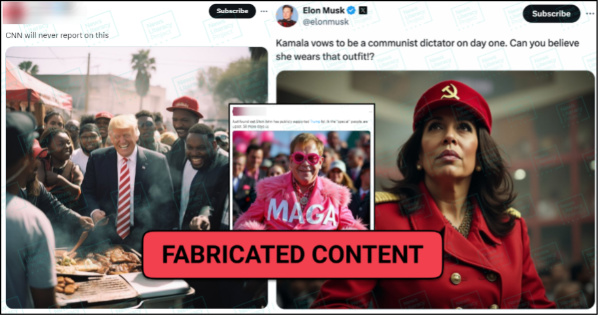
Not the main source of misinformation
Researchers have long warned that AI-generated content could release a flood of falsehoods. And while there has certainly been an uptick in these fabrications, their use in election-related rumors has not been as widespread as predicted. NLP has found that AI-generated content has been used in only about 7% of the examples we’ve documented.

Completely fabricated images of former President Donald Trump, President Joe Biden or Vice President Kamala Harris make up most of the AI-generated content in NLP’s database. These digital creations can be used to bolster a candidate’s reputation — such as fabricated images showing Biden in military fatigues or Trump praying in a church — or to denigrate their character — like fabricated images of Harris in communist garb or Trump being arrested.
AI can be used to make “photos” that distort a candidate’s relationship with certain groups or people. NLP’s database includes several AI-generated images depicting Trump with Black voters, as well as a number of images that falsely depict candidates posing with criminals or dictators, such as the late convicted sex offender Jeffrey Epstein:

The impact of AI: Question everything
Generative AI technology is behind a concerning trend in how people approach online content: fostering cynicism and “deep doubt.” It has led to a prevailing belief that it is impossible to determine if anything is real. This attitude is now being exploited by accounts falsely claiming that genuine photographs are AI creations.
When enthusiastic crowds turned out at rallies for Harris in August, falsehoods circulated online attempting to downplay the support by claiming that the visuals were AI-generated. This same tactic was used after a photograph emerged that showed a group of extended family members of vice-presidential nominee Tim Walz offering their support to Trump. The photo of Walz’s second cousins — not his immediate family — was authentic, although efforts were made to dismiss it as AI-generated.
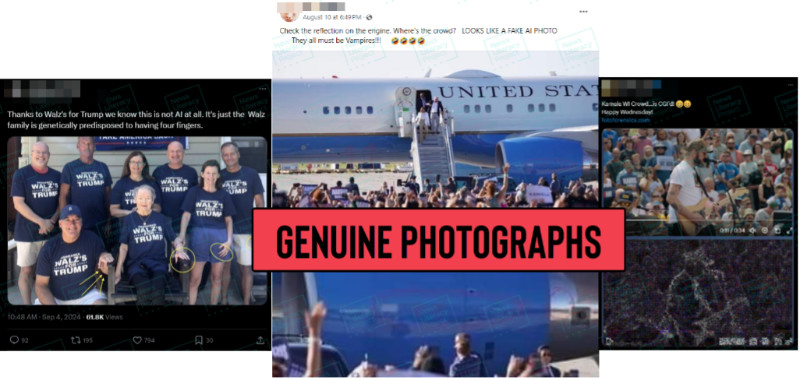
Low-tech solutions to high-tech problems
While the existence of AI fakes may make it feel like it is impossible to tell what is real, there is some good news. Whether a photograph is manipulated with computer software, an image is fabricated with an AI-image generator or a piece of media is shared out of context, the methods to identify, address and debunk these fakes remain the same.
- Consider the source. Who is sharing the content, and do they have a track record of posting accurate information in good faith?
- What is the original source of a photo? The lack of a credit is a red flag. Look for supporting evidence. Have any standards-based news outlets also shared the image?
When it comes to AI images, you may not be able to trust your own eyes. Slowing down to consider these key pieces of context is the best way to approach any content online — whether it’s real or created by AI.
Visit the Misinformation Dashboard: Election 2024
You can find additional resources to help you identify falsehoods and recognize credible election information on our resource page, Election 2024: Be informed, not misled.
Related columns:
NLP’s News Literacy District Fellowship program expands across U.S.
The News Literacy Project has selected nine school districts to join its growing News Literacy District Fellowship program — a nationwide initiative that supports education leaders to design and implement district-wide plans for news and media literacy education.
The program will potentially impact more than 1 million students across 13 states. The latest fellows are the third cohort in as many years represent districts of all sizes in urban, suburban and rural communities.
“Teaching news and media literacy to our students is no longer a supplemental skill, but a necessary one,” said Karin Ledford, librarian, Elk Grove Unified School District, California, a fellowship program participant. “Our teachers are eager to dive deep into media literacy skills, too, and are looking forward to us leading the way.”
Five California districts include Los Angeles
This 2024-25 cohort includes the Los Angeles Unified School District, the country’s second-largest, which will join four other California districts to create a blueprint for teaching all students news literacy skills before graduation that can be replicated across the state.
“Students are at a significant civic disadvantage if they are not taught how to navigate our current information landscape. Together with these districts, the News Literacy Project is leading a movement to ensure that young people learn to identify credible information and recognize falsehoods, so they graduate with the knowledge and ability to participate in civic society as well-informed, critical thinkers,” said Charles Salter, President and CEO of NLP.
The fellowship is a two-year program. Each district receives $20,000 and support from NLP through professional learning, curriculum guidance and a network of like-minded peers. Upon completion, fellows can apply to join an alumni network, demonstrating continued commitment to widespread adoption of news literacy education by mentoring and inspiring other school systems. This year’s cohort brings the total number of fellowships to 17.
“Through our fellowship and alumni programs, the News Literacy Project is sparking systemic change to public education at a national scale. Together we are paving the way for all students to graduate with news literacy skills, empowering students to think critically about information and preparing them to be active participants in our democracy,” said Shaelynn Farnsworth, director of the fellowship program.
The 2024-25 News Literacy District Fellowship cohort includes:
California
- Beverly Hills Unified School District
- Central Unified School District Fresno
- Elk Grove Unified School District
- Fremont Union High School District
- Los Angeles Unified School District
Florida
- Broward County Public Schools
Nebraska
- Kearney Public Schools, Nebraska
North Carolina
- Johnston County Public Schools
Oklahoma
- Norman Public Schools
Track the trends: Stay ahead of these election falsehoods
Welcome back to our blog series focused on the Misinformation Dashboard: Election 2024, a tool for exploring trends and analysis related to falsehoods regarding the candidates and voting process.
As of today, NLP’s Misinformation Dashboard: Election 2024 contains more than 600 hundred examples of online falsehoods. By categorizing them by themes and narratives, we provide important insights about trends and patterns in the misinformation spreading about this year’s presidential race.
The role of repetition
Ever heard the phrase, if you “repeat a lie often enough … it becomes the truth”? It’s often credited to Nazi Joseph Goebbels, one of the most notorious and malevolent propagandists in history. This law of propaganda drives much of the misinformation we find online. Our vulnerability to oft-repeated falsehoods and the “illusion of truth” effect makes it crucial to understand the common themes and narratives of viral misinformation
Candidate’s cognition a common theme
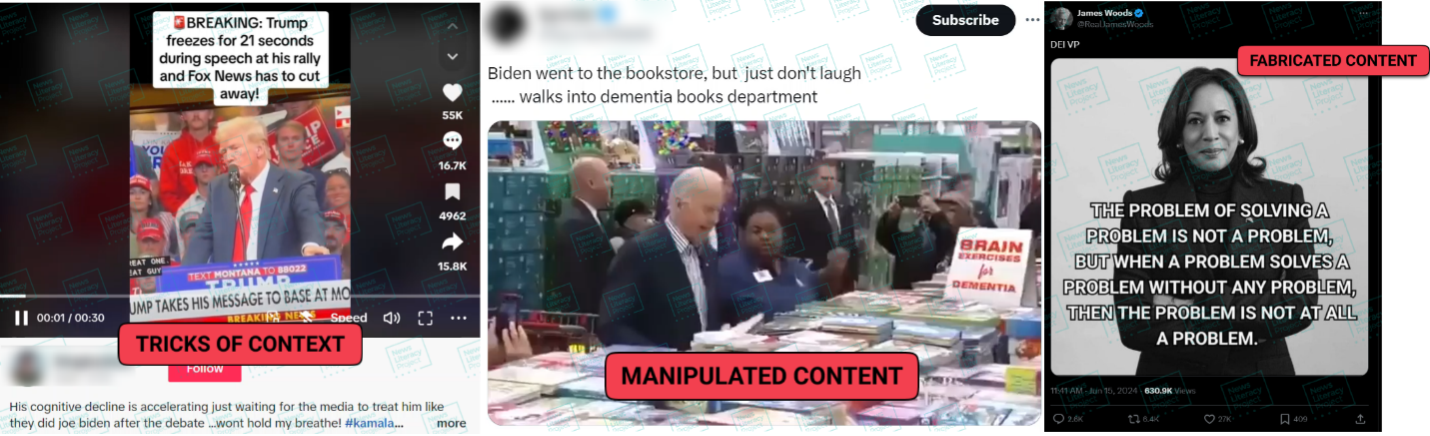
Claims that exaggerate and distort candidates’ cognitive abilities and intellect are the most frequent in our collection. This was true when President Joe Biden was the presumptive Democratic nominee running against former President Donald Trump, with many false claims attacking the candidate’s age. And the trend has continued with Vice President Kamala Harris. It’s important to note that these overall narratives are not entirely fabricated (all three politicians have had their share of public gaffes), but they appeal to our natural desire to confirm our biases, providing an exaggerated and distorted glimpse of reality in which the candidates are reduced to caricatures of themselves. Are Trump and Harris both mentally fit to be president? Our dashboard isn’t designed to answer that. But it can help to make you aware of the spate of misinformation that intends to skew your viewpoint on this question.
You can’t see the forest for the trees
Debunking individual rumors — for example, proving that Trump did not “freeze” during a campaign speech or that Harris did not say that “the problem of solving a problem is not a problem”— only partly succeeds in combating misinformation. Those who create and share misinformation are doing more than just pushing an individual falsehood. They are making a concerted and sustained effort to manipulate our political views by repeating these claims to distort consensus reality, or our shared understanding of the world around us.
We need to prepare ourselves for the inevitable false claims that will fill our news feeds in the lead up to the 2024 election. The best way to do that is to shift our attention from individual posts of questionable content and focus more on broader trends. By learning to identify the false narratives that bad actors attempt to establish about candidates and the election process, we can spot them before they draw us in.
We will continue to add every election-related viral rumor we can find to our collection through Inauguration Day on Jan. 20, 2025. So, you might want to check the dashboard’s running tally of false claims as part of your daily news routine. We also will publish analyses of political misinformation here in the weeks to come.
Track the trends: Get to know the election dashboard
Welcome to our blog series focused on the Misinformation Dashboard: Election 2024, a tool for exploring trends and analysis related to falsehoods regarding the candidates and voting process.
Every day people are bombarded with information on social media, and in this rush of content, false claims can slip by undetected. Developing the skills to identify and address falsehoods is important for every online user, especially in the days leading up to a historic presidential election, when the volume and variety ratchet up, as well as the stakes.
That’s why NLP has launched its Misinformation Dashboard: Election 2024 – an interactive collection of viral election-related falsehoods that we began compiling in July 2023, with a post from an ordinary Instagram account. The shocking image: a screenshot of what appeared to be an endorsement of Donald Trump for president from superstar Lady Gaga.
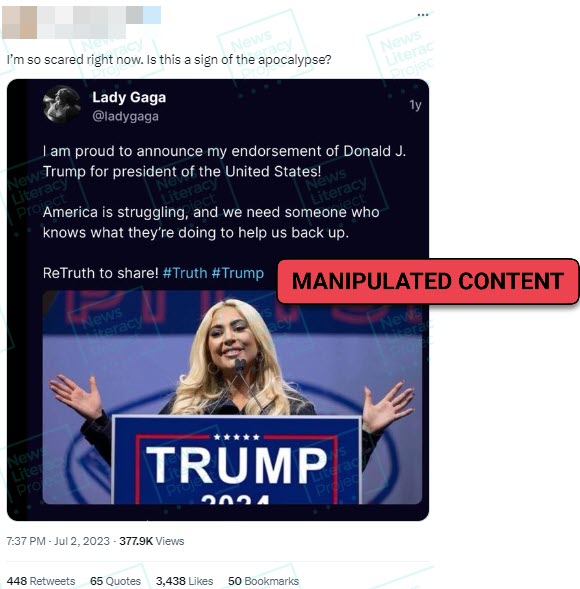
But it was not genuine. The image was created by doctoring a photograph of Gaga as she addressed a crowd in Pennsylvania during President Joe Biden’s campaign in November 2020. And the alleged quote, well, that was a complete fabrication. Since then, we’ve cataloged more than 500 other false claims aimed at influencing the electorate.
But the dashboard goes well beyond simply compiling examples of false, manipulated and AI-generated content. It identifies common tactics used to create these falsehoods, along with the recurring themes around which they cluster – an approach that we hope helps people be able to better recognize and reject these pieces of misinformation in their feeds.
The Types and Tactics of Misinformation
NLP’s Misinformation Dashboard: Election 2024 is divided into two broad sections: themes and types of misinformation.

Tricks of context have proven to be the most common form of election misinformation online so far — and the most common is the use of “false context,” or presenting an image or video along with text that inaccurately describes it. This tactic is likely popular because it is both effective and easy. False context claims often follow major breaking news events when people are following trending hashtags to get the most recent information. During a natural disaster, it is practically guaranteed that engagement seekers will post years-old photographs or videos and falsely claim that they relate to current events. The same dynamic plays out in political posts. After a campaign rally, for example, it’s not uncommon for images of large, enthusiastic crowds – such as photos of concerts – to go viral as disingenuous depictions of crowd size.
Fabricated content and manipulated content are the two other misinformation types found in the dashboard. While there have been a fair number of fabricated images created with AI-generated software, these technologically advanced falsehoods are still outpaced by less sophisticated counterparts. It is far more common to encounter a sheer assertion – an evidence-free claim that is fabricated out of thin air – or a fictional quote, than an AI-generated image. Manipulating content is another common approach to creating misinformation, with doctored images of T-shirts, signs, and news chyrons among the most common items used in these digital alterations.
Visit the Misinformation Dashboard: Election 2024
You can find additional resources to help you identify falsehoods and recognize credible election information on our resource page, Election 2024: Be informed, not misled.
Related columns:
New election misinformation dashboard tracks the trends
Election misinformation has been coming at us at such a furious clip this summer that you would have to be faster than an Olympic sprinter to outpace it. And even if you could, making sense of what you see and hear sometimes feels impossible.
That’s why we have created the Misinformation Dashboard: Election 2024. This free online resource collects examples of viral rumors, doctored images, conspiracy theories and AI-generated fakes. Because election misinformation poses an existential threat to democracy, individual fact-checks are not adequate to counter this danger.
The dashboard goes above and beyond by doing the following:
- Highlighting of-the-moment data.
- Analyzing common trends and topics within a larger context.
- Featuring dynamic visualizations that quickly illuminate information.
- Providing educators with real-time examples for the classroom and enhancing the understanding of journalists and researchers diving into election misinformation.
“Given how quickly falsehoods can congeal into deep-seated beliefs, it’s essential that all Americans learn to recognize viral election misinformation when they see it in their feeds,” said Senior Vice President of Research and Design Peter Adams, who led the development of the dashboard. “Healthy democracies flourish when civic discourse is anchored in accurate, shared understandings of issues and candidates. We hope this dashboard helps people preserve the integrity and power of their civic voices and their votes.”
Everything on the dashboard is interactive. Click on the two options at the top of it to explore election misinformation by theme or type. You’ll find examples of fabricated or manipulated content, false or misleading context and many forms of AI-generated deceptions. And we’re tracking the trends regarding election integrity, party platforms and the candidates themselves.
“Patterns in misinformation come into focus when content is collected in one place. The dashboard empowers people to see trends so they can avoid being swayed by falsehoods when they cast their votes,” said Dan Evon, NLP’s Senior Manager of Education Design, and a member of the team that developed the resource.
You can find additional resources to help you identify falsehoods and recognize credible election information on our resource page, Election 2024: Be informed, not misled.
NLP commits to systemic change in education
In my life before NLP, I was a middle school teacher, and later, a school district superintendent. These experiences were ideal preparation for doing the important work of ensuring news literacy is a national education priority.
In fact, there is a direct through line. Let me explain. When my eighth grade U.S. history students walked into the classroom, they would immediately see a large, colorful sign with one page of construction paper for each letter — THINK!
I would stand next to this sign each day and ask them questions. I didn’t realize it then, but I was challenging them to fill in the gaps of their education by asking them to think more deeply about their answers. At that time when test scores and test prep ruled the academic day, we weren’t expected to teach students to think critically. And we still don’t. That puts students at a disadvantage for life and fails a principal mandate of public education: to prepare students to be active, critically thinking members of our democracy.
NLP has led the way to help change this, and over the past year we’ve felt a renewed urgency to turn our full attention and resources to helping educators align what happens in the classroom with events in the real world.
I’m excited to announce that we have made a strategic pivot that tightens our focus on bringing systemic change to public education at a national scale. Our ultimate objective is nothing less than ensuring that news literacy becomes required teaching in all 50 states. As important and rewarding as our recent initiatives with the broader public have been, we knew we would have to restructure our work to fully leverage our expertise on this urgent initiative. Our strategic framework spells out how we will achieve this.
Partnering with Los Angeles school district
Earlier this week we took a major step toward this vision. With a three-year, $1.15 million grant from The Eli and Edythe Broad Foundation, we are partnering with the Los Angeles Unified School District (LAUSD), the second largest school district in the United States, to ensure that all students learn news literacy skills and concepts before high school graduation. LAUSD also will join NLP’s News Literacy District Fellowship program, a nationwide initiative that supports school leaders to design and implement district-wide plans for news and media literacy education that currently impacts over 1 million students in 13 states.
Together with LAUSD, we will pioneer a blueprint for news and media literacy education not just for California, but also for districts across the nation, as legislative efforts to require media literacy education gain momentum around the country.
Oh, and about that through line: As a young teacher I knew that my students didn’t need to take more tests to succeed in whatever path they chose. They needed to learn to think critically. I still believe this, and at NLP, we plan to make it happen.
NLP partners with LAUSD, Broad Foundation to create national model of news literacy learning
The Eli and Edythe Broad Foundation has awarded the News Literacy Project, the nation’s leading provider of news literacy education, a three-year, $1.15 million grant to support a partnership with Los Angeles Unified School District (LAUSD). The LAUSD is the largest independent school district in the United States, and the grant will ensure that all students learn essential news literacy skills and concepts before they graduate high school.
Through the partnership, NLP and LAUSD will pioneer a blueprint not only for districts in California seeking to align instruction with the state’s recent media literacy legislation, but also for others across the nation, as a growing number of states pass similar legislation.
“Students have a right to learn how to find information they can trust, share and act on, and they are put at a civic disadvantage for the rest of their lives if they don’t,” said Charles Salter, President and CEO of the News Literacy Project. “This partnership with The Broad Foundation and Los Angeles Unified School District will serve as a roadmap for school leaders across the country to follow and implement their own community-driven approach to news and media literacy instruction. Together, we can prepare the next generation to participate in civic life as well-informed, critical thinkers.”
Support indicates significance, urgency
This investment from The Broad Foundation represents the first time the organization has funded such a venture, marking the significance of the issue throughout the region. “Young people are growing up in an increasingly challenging and complex information landscape. The thoughtful and timely work of the News Literacy Project equips students with critical thinking skills so they can distinguish credible reporting from misinformation,” said Gerun Riley, president of The Broad Foundation. “Supporting NLP and LAUSD’s partnership is an important step in cultivating a healthy information ecosystem where L.A.’s students can find and use trustworthy information to make well-informed decisions and uplift our communities.”
Philanthropist Melanie Lundquist brought together the partnership among The Broad Foundation, LAUSD and NLP. “I am grateful to The Broad Foundation for their support of NLP and proud of LA Unified, of which I am an alum. This collaboration sends a strong message that in Los Angeles, our young people will be well-equipped to become active and informed citizens. This is not a partisan issue. The News Literacy Project sets the standard for impartial media literacy education, and that helps strengthen our democracy,” said Lundquist, who is the largest individual donor to NLP and a member of NLP’s Board of Directors.
LAUSD to join District Fellowship program
Beginning in the 2024-25 school year, LAUSD will join the News Literacy District Fellowship program, a nationwide initiative that supports school leaders to design and implement their own innovative, sustainable plans for news and media literacy education for all students in their districts.
“Protecting democracy starts in America’s classrooms, and I appreciate The Broad Foundation’s commitment to our students and teachers in advancing news literacy curriculum,” said LAUSD Superintendent Alberto M. Carvalho. “In addition to our recent investment of $2 million in state monies to support educators to develop content, we are pleased to partner with organizations like NLP to implement media literacy education across our District. This collaboration will set the standard for effective news literacy instruction in classrooms across the country.”
NLP provides professional learning for administrators and educators and curriculum resources such as The Sift® newsletter and Checkology®, an award-winning e-learning platform for teaching news literacy. To learn more, read about the work of educators in New Mexico who have just completed their fellowship.
NLP expert shares strategies to spot and stop misinformation on AARP podcast In Clear Terms
We are all susceptible to misinformation, but news literacy skills can protect you from being misled. On the In Clear Terms podcast, presented by the AARP, NLP Senior Manager of Education Design Dan Evon emphasizes the importance of verifying content before sharing it.
“If we can resist engaging with this content, resist sharing this content, we can really dampen its spread. And the less it spreads, the less it fools people and the less power it has,” Evon says.
NLP’s Five Factors teaches people how to evaluate the credibility of news and information.
Listen to the full episode here.
New Mexico educators look to expand news literacy beyond their district

Joel Hutchinson and Josefina Miller at a News Literacy District Fellowship retreat.
For years, educators have had a front-row seat to the often-troubling impacts of the information technology revolution on their teaching and on young people. To help ensure their students can thrive in a world where misinformation pollutes a relentless stream of online content, a team of educators in Las Cruces, New Mexico, turned to the News Literacy Project.
“Media technology is shifting far faster than we can keep up with it. Most students are getting news from TikTok and other ‘news’ sources. This was driving our thinking,” said Joel Hutchinson, secondary English language arts content specialist for Las Cruces public schools, a district with 25,000 students.
In 2021, Hutchinson, secondary Social Studies Content Specialist Jamie Patterson, and middle school English language arts Content Lead Josefina Miller applied to NLP’s News Literacy District Fellowship program. They were accepted into the inaugural cohort in 2022.
During the two-year fellowship, districts partner with NLP to develop and implement innovative, sustainable initiatives to embed news and media literacy education in their schools. Shaelynn Farnsworth, director of the program, credits the Las Cruces team with involving cross-curricular leaders and support staff to tackle the challenge. “Right from day one they met regularly and built a plan. They are of one of our strongest fellowship districts and are a model for the state.”
The educators consider news literacy instruction an educational imperative and believe a lack of news literacy skills disempowers students. “It’s a necessity. We need to start as early as possible because we know that our students have access to all forms of technology at very early ages,” Miller said.
It starts with the teachers
Patterson noted how her son, age 5, likes to watch videos of tornadoes on YouTube and can’t tell what is fake and what isn’t. “It was a big ‘Aha!’ moment for me. He hasn’t even started school yet, and he’s already seeing these videos and everything else, and they’re forming what he understands about the world. And that’s a problem.”
But before they could roll out news literacy instruction, the team needed to provide teachers with the support to integrate it in their classrooms. They piloted professional development with a group of high school ELA and social studies educators, building much of the curriculum around NLP’s signature digital learning platform, Checkology®.
“We have teacher leaders who experimented and tried things out, and they’re now the ones that are helping us grow the program over the next few years,” Patterson said.
 Las Cruces educators Megan Belch and Chelsea Lester participate in a critical observation exercise to vet the legitimacy of an image and its use at a professional learning event.
Las Cruces educators Megan Belch and Chelsea Lester participate in a critical observation exercise to vet the legitimacy of an image and its use at a professional learning event. A poster created by a Las Cruces educator at a professional learning event.
A poster created by a Las Cruces educator at a professional learning event.The fellowship gave the educators the time and resources to focus and plan each step of the process, Hutchinson said.
“Because we had a preview with the pilot and the feedback from our colleagues, we can trickle down the skills from secondary level into middle school,” eventually incorporating news literacy instruction into elementary school, Miller noted.
News literacy instruction has been implemented in all Principals of Democracy classes, a course for upper grade levels, and it’s been written into the social studies curriculum guide for seniors. Students are introduced to news literacy at the start of the school year, and it is woven into class instruction throughout the year, so concepts are constantly reinforced.
Looking beyond their borders
What also sets the Las Cruces fellows apart is their vision of establishing news literacy education as a priority for all students in New Mexico, Farnsworth said. “They are working at the regional and state levels to help inform legislative decisions.”
And the educators hope to continue to advocate for news literacy at home while also assisting other districts as participants in NLP’s News Literacy District Fellowship Alumni program.
To have a meaningful impact, this work can’t start soon enough, the educators say. “What success would look like is to see this as a common practice, just part of the conversation. If we want to prepare kids for tomorrow, you’ve got to be thinking about tomorrow,” Patterson said.
Fellowship Highlights
- The Las Cruces fellowship team built on government momentum after New Mexico directed the Department of Education to develop and implement plans to include professional development for teaching digital citizenship, of which news literacy is a component. Among the efforts:
- Hosting and presenting at statewide ed tech and social studies conferences.
- Working with civic groups, such as The League of Women Voters, to advocate that news literacy is essential for a robust democracy.
- Las Cruces educators created fellowship digital portfolios documenting their implementation of news literacy instruction into their teaching, including:
- News literacy professional learning.
- Classroom and student achievement.
- Plans for continued implementation.
Statement on the attempted assassination of former President Trump and the mis- and disinformation in its aftermath:
At the News Literacy Project, we join others in America deeply troubled by the attempt on former President Donald Trump’s life on July 13. While thankful that he was not seriously injured, we extend our condolences to the family of Corey Comperatore, a firefighter, father and husband who lost his life. We also send our wishes for a swift and full recovery to the two other men who were injured in the shooting. Political violence should hold no place in our democratic process and civic discourse.
Immediately after the shooting, rumors and unverified claims emanated from across the political spectrum and spread rapidly online. In breaking news situations, the facts constantly evolve during the hours that follow, and even in the days and weeks after. We should avoid the temptation to propagate opinions that could further fuel false and unverified claims, expand the reach of propaganda and hate speech, and potentially lead to further violence. We all are susceptible to confirmation bias because many of us live in media echo chambers that reinforce our beliefs and leave us blind to new facts that can put an event in context and improve our understanding of it.
For helpful resources on how to evaluate breaking news, avoid confirmation bias and understand conspiratorial thinking, follow our social media channels and visit our website, where we provide additional resources to help promote informed news consumption and empower you to combat the spread of harmful falsehoods.
Celebrate Juneteenth with facts, not falsehoods
Today NLP recognizes and celebrates Juneteenth, which became an official U.S. holiday in 2021. The designation commemorates the events of June 19, 1865, when federal troops freed the last of our nation’s enslaved people, who were being held by the Confederacy in Galveston, Texas.
More than two and a half years earlier, on Jan. 1, 1863, President Abraham Lincoln signed the Emancipation Proclamation, freeing all of those enslaved in the U.S. But news of freedom alone did not equal liberation. For those enslaved in Galveston, it finally arrived when Union troops defeated the Confederacy there in June 1865, more than two months after Confederate General Robert E. Lee surrendered to the Union Army, ending the Civil War.
Also known as Freedom Day or Emancipation Day, Juneteenth is the oldest known celebration marking the end of slaveryin the U.S. The National Museum of African American History & Culture declares it “our country’s second independence day” and notes that its enduring legacy indicates “the value of never giving up hope in uncertain times.”
Myths and misinformation
As with any important day in U.S. history, misinformation about Juneteenth abounds. One common misperception is that enslaved people were unaware that the Emancipation Proclamation had freed them in 1863. Alexa Volland, NLP’s senior manager of multimedia content, clears things up in this short video. To steer clear of misinformation about Juneteenth, seek out standards-based sources and don’t assume everything you see about the holiday — especially posts on social media that trigger strong emotional reactions— is credible.
We encourage you to join the News Literacy Project in celebrating Juneteenth and learning more about its history and meaning. This Smithsonian piece is a good place to start, and this New York Times interactive article from 2020 puts Juneteenth in perspective. For those marking the holiday for the first time, the Associated Press published this guidanceyesterday.
For more on the Juneteenth holiday, check out our Flipboard collection of articles and resources.